
시리즈를 마무리하며 — 에이전트를 “서비스”로 바꾸는 마지막 퍼즐
1편에서 코어 메커니즘을 해부하고, 2편에서 슬래시 커맨드로 세션을 다스리며, 3편에서 MCP·플러그인·스킬로 외연을 넓혔습니다. 4편(상)에서는 Hooks로 에이전트에 안전망을 씌웠고, 4편(하)에서는 Subagent 오케스트레이션으로 1인 다역 체계를 구축했죠. 이 모든 Claude Code 활용법이 결국 향하는 곳은 하나입니다 — “사람이 자리를 비워도 에이전트가 일을 계속하는 환경”. 오늘 다룰 Remote Control, Cloud 환경, 샌드박스 보안, 그리고 관측(Observability)은 바로 그 24/7 운영을 실현하는 인프라 계층입니다.
이 글을 읽고 나면, Claude Code를 터미널에서 꺼내 CI 파이프라인·모바일 알림·스케줄 잡으로 연결하고, 비용과 실패 패턴까지 대시보드로 추적하는 전체 그림을 그릴 수 있게 될 것입니다.
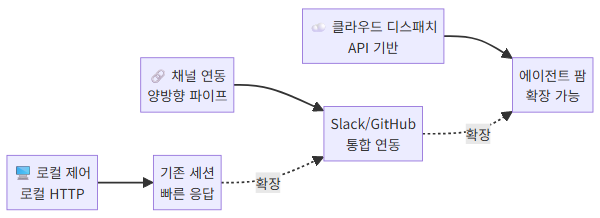
1. Remote Control — 터미널 밖에서 에이전트를 조종하다
1-1. Remote Control이 필요한 순간
Claude Code는 기본적으로 인터랙티브 터미널 세션입니다. 하지만 현실에서는 터미널 앞에 앉아 있지 않은 상태에서 에이전트를 제어해야 하는 경우가 빈번합니다. CI/CD 파이프라인에서 PR을 자동 리뷰하거나, 모바일에서 긴급 패치를 지시하거나, 슬랙 봇이 이슈를 받아 자동으로 코드를 생성하는 시나리오가 대표적입니다.
Anthropic은 이를 위해 세 가지 원격 제어 메커니즘을 제공합니다: Remote Control, Channels, Dispatch. 이 셋은 추상화 수준과 사용 맥락이 다릅니다.
1-2. Remote Control API — 로컬 에이전트의 HTTP 인터페이스
Remote Control은 이미 실행 중인 Claude Code 세션에 HTTP로 메시지를 주입하는 메커니즘입니다. --remote-control 플래그로 세션을 시작하면, 로컬에 경량 HTTP 서버가 함께 뜹니다.
# 세션 시작 시 Remote Control 활성화
claude --remote-control
# 별도 터미널에서 메시지 전송
curl -X POST http://localhost:19785/message \
-H "Content-Type: application/json" \
-d '{"message": "src/auth.ts 파일의 JWT 검증 로직을 리팩터링해줘"}'
핵심 포인트를 정리하면 다음과 같습니다:
- 로컬 전용: 기본적으로 localhost에만 바인딩됩니다. 보안상 외부 노출은 권장되지 않습니다.
- 양방향 통신: WebSocket 업그레이드를 지원해 스트리밍 응답을 실시간으로 받을 수 있습니다.
- 세션 유지: 기존 세션의 컨텍스트가 그대로 유지되므로, 이전 대화를 이어서 작업 지시가 가능합니다.
- 권한 계승: 세션 시작 시 설정한 권한 모드(Plan/Auto/Default)가 원격 명령에도 동일하게 적용됩니다.
Remote Control의 진짜 힘은 다른 프로그램이 Claude Code를 도구로 사용할 수 있게 만든다는 점입니다. 예를 들어 슬랙 봇이 사용자 메시지를 받아 Remote Control API로 전달하고, 응답을 다시 슬랙에 포스팅하는 구조가 가능합니다.
1-3. Channels — 지속적 연결 파이프
Remote Control이 “이미 떠 있는 세션에 메시지를 보내는 것”이라면, Channels는 에이전트와 외부 시스템 사이에 지속적인 양방향 파이프를 설정하는 개념입니다.
# 채널을 통한 세션 시작
claude --channel slack-ops \
--channel-config '{"webhook":"https://hooks.slack.com/...", "thread_ts":"..."}'
Channels의 핵심 특성은 다음과 같습니다:
- Named Channel: 채널에 이름을 부여해 여러 외부 시스템을 동시에 연결할 수 있습니다. 하나의 에이전트가 Slack, GitHub, Jira 채널을 동시에 리슨하는 구조입니다.
- 이벤트 기반 트리거: 외부 시스템에서 이벤트가 발생하면 자동으로 에이전트에 전달됩니다.
- 응답 라우팅: 에이전트의 응답이 원래 채널로 자동 라우팅됩니다. Slack에서 온 질문은 Slack으로, GitHub에서 온 리뷰 요청은 GitHub PR 코멘트로 돌아갑니다.
- 세션 격리: 채널별로 독립 세션을 유지할 수 있어, 한 채널의 컨텍스트가 다른 채널을 오염시키지 않습니다.
Remote Control과 Channels의 관계를 비유하면, Remote Control은 “무전기로 한 마디 보내는 것”이고, Channels은 “전화선을 개설하는 것”입니다.
1-4. Dispatch — 에이전트를 원격에서 생성하고 관리하기
Dispatch는 가장 높은 수준의 추상화입니다. 에이전트 세션 자체를 프로그래밍적으로 생성·관리·종료합니다.
# Dispatch API로 새 에이전트 세션 생성
curl -X POST https://api.anthropic.com/v1/claude-code/dispatch \
-H "Authorization: Bearer $API_KEY" \
-H "Content-Type: application/json" \
-d '{
"task": "PR #142의 변경사항을 리뷰하고 코멘트를 남겨줘",
"repo": "https://github.com/myorg/myrepo",
"ref": "feature/auth-refactor",
"permissions": "plan",
"timeout_minutes": 30,
"on_complete": {
"webhook": "https://myserver.com/hooks/dispatch-done"
}
}'
Dispatch의 핵심 가치는 “에이전트 팜(Agent Farm)” 구축입니다:
- 온디맨드 생성: 필요할 때 에이전트를 띄우고, 작업이 끝나면 자동 정리합니다.
- 병렬 실행: 여러 Dispatch를 동시에 발행해 PR 10개를 병렬 리뷰하거나, 모노레포의 패키지별 테스트를 동시 실행합니다.
- 상태 추적: 각 Dispatch에 고유 ID가 부여되어, 진행 상황 조회·중단·재시작이 가능합니다.
- 결과 수집: 완료 시 웹훅으로 결과를 받거나, 폴링으로 상태를 확인합니다.
세 메커니즘을 정리하면 다음과 같습니다:
| 메커니즘 | 세션 관리 | 통신 방식 | 주요 용도 |
|---|---|---|---|
| Remote Control | 기존 세션 활용 | 로컬 HTTP | IDE 통합, 로컬 자동화 |
| Channels | 기존 세션 + 채널 추가 | 양방향 파이프 | Slack/GitHub 연동 |
| Dispatch | 새 세션 생성 | 클라우드 API | CI/CD, 에이전트 팜 |
1-5. 모바일·CI 환경에서의 실전 활용
모바일 제어 시나리오: Anthropic Console 모바일 앱 또는 Telegram 봇을 통해 Dispatch API를 호출하는 구조를 만들 수 있습니다. 출퇴근 지하철에서 “오늘 들어온 이슈 3건 분석해줘”라고 메시지를 보내면, 클라우드의 에이전트가 작업을 수행하고 결과를 다시 모바일로 보내주는 워크플로우입니다.
CI 환경 시나리오: GitHub Actions에서 Dispatch를 호출하는 패턴이 특히 강력합니다.
# .github/workflows/claude-review.yml
name: Claude Code PR Review
on:
pull_request:
types: [opened, synchronize]
jobs:
review:
runs-on: ubuntu-latest
steps:
- uses: anthropic/claude-code-action@v1
with:
api-key: ${{ secrets.ANTHROPIC_API_KEY }}
task: |
이 PR의 변경사항을 리뷰해줘.
보안 취약점, 성능 이슈, 코드 스타일을 확인하고
라인별 코멘트를 남겨줘.
permissions: plan
timeout: 15m
이 GitHub Action은 내부적으로 Dispatch API를 사용합니다. PR이 열리거나 업데이트될 때마다 자동으로 에이전트가 리뷰를 수행하고, 결과를 PR 코멘트로 남깁니다.
2. Scheduled Tasks와 Cloud 환경 — 무인 자동화의 핵심

2-1. Scheduled Tasks — 반복 작업의 자동화
2편에서 /schedule 커맨드를 소개했었는데, 이번에는 그것이 실제로 어떤 인프라 위에서 돌아가는지를 깊이 파고듭니다.
Scheduled Tasks는 크게 두 가지 실행 환경을 가집니다:
- 로컬 스케줄링:
/schedule로 등록한 태스크가 로컬 머신의 cron 데몬(Linux/macOS) 또는 Task Scheduler(Windows)에 등록됩니다. 머신이 꺼지면 실행되지 않습니다. - Anthropic-managed 클라우드 스케줄링: 태스크를 Anthropic의 관리형 인프라에서 실행합니다. 24/7 보장이 필요한 작업에 적합합니다.
# 로컬 스케줄링 — 매일 오전 9시 보안 스캔
/schedule "daily-security" --cron "0 9 * * *" \
--task "프로젝트의 의존성 보안 취약점을 스캔하고 리포트를 생성해줘"
# 클라우드 스케줄링 — 매시간 모니터링
/schedule "hourly-health" --cron "0 * * * *" \
--cloud \
--task "프로덕션 로그에서 에러 패턴을 분석하고,
임계값 초과 시 Slack #alerts에 알림을 보내줘" \
--on-failure "webhook:https://myserver.com/schedule-fail"
2-2. Anthropic-managed 클라우드 환경의 구조
클라우드 스케줄링을 선택하면, 태스크는 Anthropic이 관리하는 격리된 컨테이너 환경에서 실행됩니다. 이 환경의 특성을 이해하는 것이 중요합니다:
- 에피메럴 환경: 태스크마다 새로운 컨테이너가 생성되고, 완료 후 파기됩니다. 상태를 유지하려면 외부 스토리지(S3, Git 등)에 명시적으로 저장해야 합니다.
- 레포지토리 클론: 지정한 Git 레포지토리를 자동으로 클론한 뒤 작업을 수행합니다. SSH 키나 토큰은 암호화된 시크릿 스토어에서 주입됩니다.
- 네트워크 제한: 기본적으로 외부 네트워크 접근이 제한되며, 허용 목록(allowlist)에 등록된 엔드포인트만 접근 가능합니다.
- 리소스 제한: CPU, 메모리, 실행 시간에 상한이 있습니다. 기본 타임아웃은 30분이며, 최대 2시간까지 확장 가능합니다.
2-3. Cloud Auto-fix — 무인 PR 워크플로우의 완성
Cloud Auto-fix는 Scheduled Tasks와 Dispatch를 결합한 고급 패턴입니다. CI에서 테스트가 실패하면, 자동으로 에이전트가 수정을 시도하고 새 커밋을 푸시하는 구조입니다.
# settings.json — Cloud Auto-fix 설정
{
"cloud": {
"autofix": {
"enabled": true,
"triggers": ["ci_failure", "security_alert", "dependency_update"],
"max_attempts": 3,
"branch_prefix": "claude/autofix-",
"require_review": true,
"allowed_file_patterns": ["src/**", "tests/**"],
"blocked_file_patterns": [".env*", "*.key", "infrastructure/**"]
}
}
}
이 설정이 활성화되면 다음과 같은 흐름이 자동으로 진행됩니다:
- CI 파이프라인에서 테스트 실패 이벤트 발생
- 웹훅이 Dispatch API를 호출해 Auto-fix 에이전트 생성
- 에이전트가 실패 로그를 분석하고 수정 코드 작성
claude/autofix-{issue-id}브랜치에 커밋·푸시- 자동으로 PR 생성 (require_review: true이므로 사람의 승인 필요)
- PR이 승인·머지되면 원본 CI가 다시 실행
핵심은 require_review: true입니다. 완전 무인이 아니라 “사람의 승인”이라는 관문을 유지하면서도, 수정 코드 작성이라는 노동 집약적 단계를 자동화하는 것입니다.
2-4. Scheduled Tasks + Subagents + Hooks 결합 패턴
이전 편에서 다룬 Subagents와 Hooks를 Scheduled Tasks와 결합하면, 진정한 무인 운영 체계가 완성됩니다.
# CLAUDE.md — 야간 무인 운영 설정
## Scheduled Maintenance Agent
이 프로젝트에는 야간 유지보수 스케줄이 등록되어 있습니다.
### 태스크 목록
1. **의존성 업데이트** (매주 월요일 02:00)
- Subagent "dependency-checker"가 outdated 패키지 스캔
- Subagent "test-runner"가 업데이트 후 전체 테스트 실행
- Hook: PostToolUse에서 breaking change 감지 시 롤백
2. **코드 품질 리포트** (매일 06:00)
- 정적 분석, 커버리지, 복잡도 지표 수집
- Markdown 리포트 생성 → GitHub Wiki에 자동 업로드
3. **보안 스캔** (매일 03:00)
- npm audit, Snyk, CodeQL 결과 통합
- Critical/High 발견 시 Slack #security에 즉시 알림
이 구성에서 각 편의 기능이 어떻게 맞물리는지 보세요:
- Scheduled Tasks(5편): 태스크 트리거와 실행 주기
- Subagents(4편 하): 역할별 에이전트 분리로 효율적 처리
- Hooks(4편 상): 안전장치와 자동 게이팅
- MCP(3편): 외부 서비스(Slack, GitHub, Jira) 연동
- 세션 관리(2편): /resume으로 이전 맥락 이어받기
- 컨텍스트 운용(1편): 긴 작업에서의 /compact와 메모리 관리
3. 샌드박스 보안 모델 — 에이전트에게 자유를 주되, 울타리를 세우다
3-1. 왜 샌드박스가 필요한가
에이전트에게 코드 실행 권한을 주는 순간, 보안은 최우선 과제가 됩니다. 특히 --dangerously-skip-permissions나 Auto mode에서 에이전트가 임의의 명령을 실행할 수 있을 때, 한 줄의 rm -rf /가 시스템 전체를 날릴 수 있습니다. Claude Code의 샌드박스 모델은 이런 위험을 구조적으로 차단합니다.
3-2. PID Namespace 격리
Linux 환경에서 Claude Code는 PID namespace 격리를 사용합니다. 에이전트가 실행하는 모든 자식 프로세스는 별도의 PID 네임스페이스에서 생성됩니다.
# 에이전트가 실행한 프로세스의 실제 격리 상태
$ cat /proc/self/status | grep NSpid
NSpid: 12345 1
# 에이전트의 자식 프로세스는 호스트의 다른 프로세스를 볼 수 없음
$ ps aux # 에이전트 컨텍스트 내에서
PID USER COMMAND
1 claude /bin/bash
15 claude node src/index.js
23 claude npm test
이것이 의미하는 바는 명확합니다:
- 에이전트가
kill -9을 실행해도 자신의 네임스페이스 안의 프로세스만 영향을 받습니다. - 호스트 시스템의 프로세스 목록을 열람할 수 없어 정보 유출이 차단됩니다.
- 에이전트가 종료되면 네임스페이스 전체가 정리되어 좀비 프로세스가 남지 않습니다.
3-3. Child Process Sandbox
PID 격리 위에, Claude Code는 자식 프로세스에 추가적인 샌드박스를 적용합니다. 이는 seccomp-bpf(Linux) 또는 Sandbox(macOS)를 활용합니다.
# 샌드박스 정책 예시 (내부 구현, 개념 설명용)
{
"sandbox_policy": {
"filesystem": {
"read": ["/workspace/**", "/tmp/**", "/usr/lib/**"],
"write": ["/workspace/**", "/tmp/**"],
"deny": ["/etc/shadow", "/root/**", "~/.ssh/**"]
},
"network": {
"allow_outbound": ["443", "80", "22"],
"deny_inbound": true,
"deny_raw_sockets": true
},
"process": {
"max_children": 50,
"max_memory_mb": 4096,
"max_cpu_seconds": 600,
"deny_ptrace": true
}
}
}
이 정책의 핵심 원칙은 “최소 권한(Least Privilege)”입니다:
- 파일시스템: 작업 디렉터리와 임시 디렉터리만 쓰기 가능. 시스템 설정 파일이나 SSH 키는 읽기조차 차단됩니다.
- 네트워크: 아웃바운드 HTTPS/HTTP/SSH만 허용. 인바운드 연결과 raw socket(패킷 스니핑)은 차단됩니다.
- 프로세스: 포크 폭탄 방지를 위한 자식 프로세스 수 제한, 메모리/CPU 상한 설정, ptrace(디버거 attach) 차단.
3-4. OS CA 신뢰와 네트워크 보안
Claude Code가 외부 서비스(GitHub, npm registry, MCP 서버 등)와 통신할 때의 TLS 처리도 보안 모델의 중요한 부분입니다.
OS CA 신뢰(OS Certificate Authority Trust)란, Claude Code가 HTTPS 연결 시 운영체제의 CA 인증서 저장소를 신뢰한다는 의미입니다. 이것이 왜 중요한지 살펴보겠습니다:
- 기업 환경 호환성: 기업 내부에서 자체 CA를 사용하는 경우(사내 프록시, 사설 레지스트리 등), OS CA 저장소에 해당 CA 인증서를 추가하면 Claude Code도 자동으로 신뢰합니다. 별도의 설정이 필요 없습니다.
- 중간자 공격 방지: 신뢰되지 않는 인증서를 사용하는 연결은 차단됩니다. 에이전트가 악의적인 MCP 서버에 연결되는 것을 방지합니다.
- 인증서 고정(Pinning) 없음: Anthropic API 연결에 대해 인증서 고정을 하지 않아, 기업 TLS 검사(inspection) 프록시와 호환됩니다.
# 기업 환경에서 사내 CA 추가 예시
# 1. OS CA 저장소에 사내 CA 추가 (Ubuntu)
sudo cp internal-ca.crt /usr/local/share/ca-certificates/
sudo update-ca-certificates
# 2. Claude Code는 자동으로 사내 CA를 신뢰
# 별도 설정 불필요 — OS CA 저장소를 그대로 따름
# 3. NODE_EXTRA_CA_CERTS 환경변수도 지원
export NODE_EXTRA_CA_CERTS=/path/to/internal-ca.crt
3-5. 보안 계층의 전체 구조
Claude Code의 보안은 단일 메커니즘이 아니라 다층 방어(Defense in Depth)로 구성됩니다. 1편에서 다룬 입력·출력 이중 분류기부터 시작해, 이번 편의 샌드박스까지 전체 계층을 정리하겠습니다:
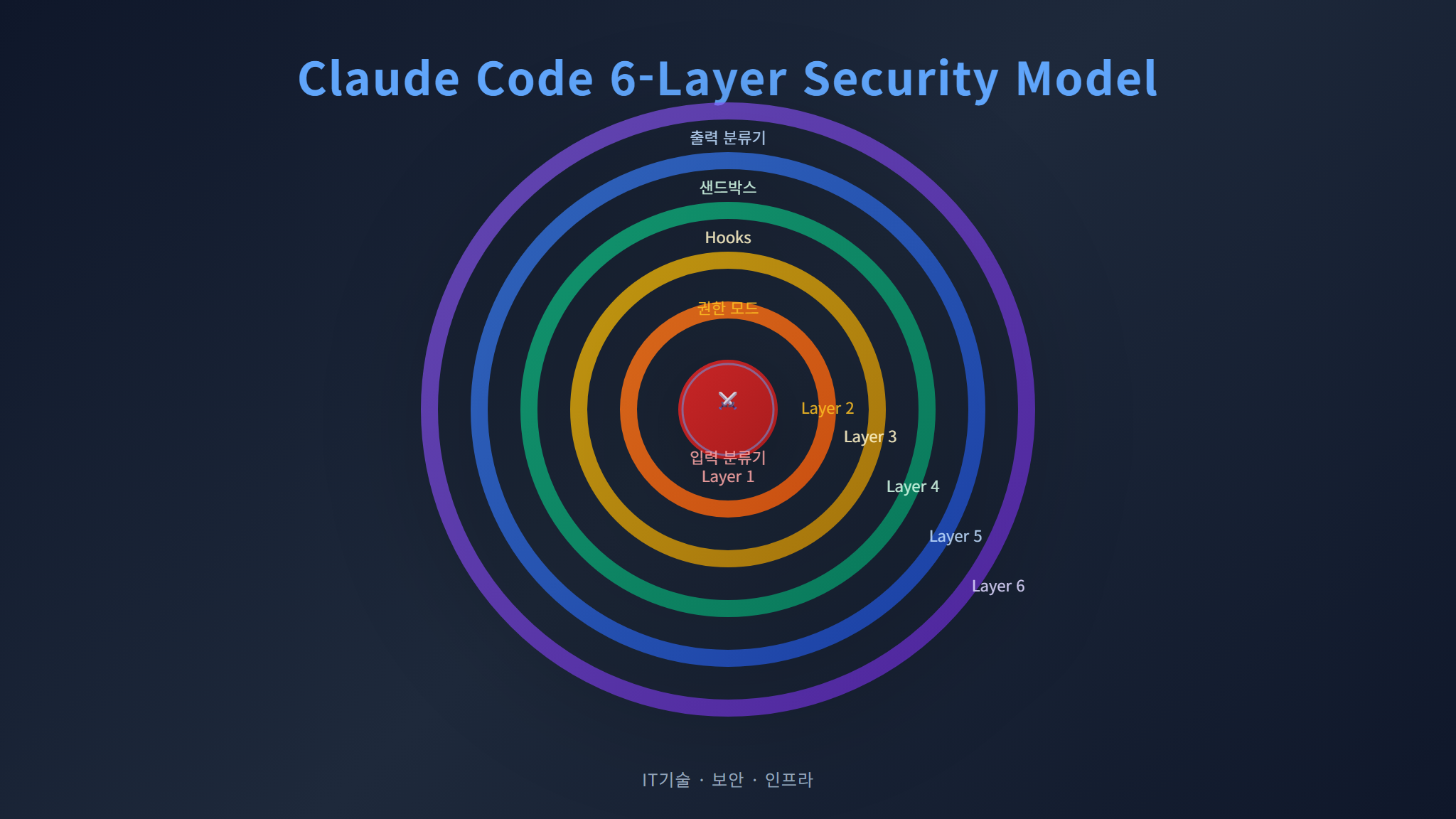
- Layer 1 — 입력 분류기: 프롬프트 인젝션, 악의적 지시 필터링 (1편)
- Layer 2 — 권한 모드: Plan/Default/Auto 모드별 도구 사용 제한 (1편)
- Layer 3 — Hooks: PreToolUse/PostToolUse에서 커스텀 검증 (4편 상)
- Layer 4 — 샌드박스: PID 격리, 파일시스템/네트워크 제한 (5편)
- Layer 5 — 출력 분류기: 생성된 코드·명령의 위험도 평가 (1편)
- Layer 6 — 감사 로그: 모든 도구 호출과 결과의 기록 (5편)
이 6개 계층 중 어느 하나가 뚫려도, 나머지 계층이 안전망으로 작동합니다. 이것이 에이전트 보안의 핵심 철학입니다.
4. OpenTelemetry와 Enterprise Analytics — 에이전트를 관측하다
4-1. 관측 가능성(Observability)이 왜 중요한가
“측정할 수 없으면 관리할 수 없다”는 피터 드러커의 격언은 에이전트 운영에도 그대로 적용됩니다. 특히 24/7 무인 운영에서는 다음 질문에 답할 수 있어야 합니다:
- 에이전트가 하루에 API 토큰을 얼마나 소비하는가?
- 어떤 태스크가 가장 비용 효율적이고, 어떤 태스크가 돈을 낭비하는가?
- 실패하는 패턴이 있는가? 특정 시간대, 특정 유형의 작업에서 실패율이 높은가?
- Subagent 간 작업 분배가 균형 잡혀 있는가?
4-2. OpenTelemetry 통합 — 표준 관측 프레임워크
Claude Code는 OpenTelemetry(OTel) 표준을 지원합니다. OTel은 분산 시스템의 트레이스, 메트릭, 로그를 수집하는 CNCF 표준 프레임워크입니다.
# OpenTelemetry 수집기 설정
# settings.json
{
"telemetry": {
"enabled": true,
"exporter": "otlp",
"endpoint": "http://otel-collector:4317",
"protocol": "grpc",
"headers": {
"Authorization": "Bearer ${OTEL_AUTH_TOKEN}"
},
"resource_attributes": {
"service.name": "claude-code",
"service.version": "1.0.0",
"deployment.environment": "production",
"team.name": "platform-engineering"
},
"sampling": {
"strategy": "parentbased_traceidratio",
"ratio": 1.0
}
}
}
Claude Code가 내보내는 OTel 데이터의 구조를 살펴보겠습니다:
Traces (분산 추적):
# 트레이스 구조 예시
Trace: session-abc123
├── Span: user_prompt "PR 리뷰해줘"
│ ├── Span: tool_call "Read" (src/auth.ts)
│ │ └── Attribute: file_size=2048, duration_ms=15
│ ├── Span: tool_call "Grep" (pattern="password")
│ │ └── Attribute: matches=3, duration_ms=42
│ ├── Span: subagent_dispatch "security-reviewer"
│ │ ├── Span: tool_call "Bash" (npm audit)
│ │ │ └── Attribute: exit_code=1, vulnerabilities=2
│ │ └── Span: tool_call "Write" (security-report.md)
│ └── Span: api_call "claude-opus-4-6"
│ └── Attribute: input_tokens=15234, output_tokens=3421,
│ cache_hit_tokens=12000, cost_usd=0.087
각 스팬(Span)은 하나의 작업 단위를 나타냅니다. 도구 호출, API 호출, 서브에이전트 실행 등이 모두 스팬으로 기록되어 전체 작업 흐름을 추적할 수 있습니다.
Metrics (지표):
# Claude Code가 내보내는 주요 메트릭
claude_code_session_duration_seconds # 세션 지속 시간
claude_code_tool_calls_total # 도구 호출 횟수 (도구별 레이블)
claude_code_api_tokens_used_total # API 토큰 사용량 (input/output별)
claude_code_api_cost_usd_total # 누적 비용 (USD)
claude_code_prompt_cache_hit_ratio # 프롬프트 캐시 적중률
claude_code_subagent_spawns_total # 서브에이전트 생성 횟수
claude_code_tool_errors_total # 도구 실행 에러 횟수
claude_code_hook_blocks_total # 훅에 의한 차단 횟수
claude_code_sandbox_violations_total # 샌드박스 위반 시도 횟수
이 메트릭들을 Prometheus로 수집하고 Grafana로 시각화하면, 에이전트 운영의 전체 상황을 한눈에 파악할 수 있습니다.
4-3. Grafana 대시보드 구성 예시
실전에서 유용한 대시보드 패널 구성을 소개합니다:
# Panel 1: 일별 비용 추이
# PromQL
sum(rate(claude_code_api_cost_usd_total[24h])) by (task_type)
# Panel 2: 도구별 호출 빈도 (Top 10)
# PromQL
topk(10, sum(rate(claude_code_tool_calls_total[1h])) by (tool_name))
# Panel 3: 캐시 적중률 추이
# PromQL
claude_code_prompt_cache_hit_ratio
# Panel 4: 에러율 (도구별)
# PromQL
sum(rate(claude_code_tool_errors_total[1h])) by (tool_name)
/ sum(rate(claude_code_tool_calls_total[1h])) by (tool_name)
# Panel 5: 서브에이전트 작업 분포
# PromQL
sum(claude_code_subagent_spawns_total) by (agent_name)
알림 규칙 설정:
# Grafana Alert Rules
groups:
- name: claude-code-alerts
rules:
- alert: HighCostAnomaly
expr: |
sum(rate(claude_code_api_cost_usd_total[1h])) > 5.0
for: 10m
labels:
severity: warning
annotations:
summary: "Claude Code 시간당 비용이 $5를 초과했습니다"
- alert: HighErrorRate
expr: |
sum(rate(claude_code_tool_errors_total[15m]))
/ sum(rate(claude_code_tool_calls_total[15m])) > 0.3
for: 5m
labels:
severity: critical
annotations:
summary: "도구 에러율이 30%를 초과했습니다"
- alert: SandboxViolation
expr: |
increase(claude_code_sandbox_violations_total[5m]) > 0
labels:
severity: critical
annotations:
summary: "샌드박스 위반 시도가 감지되었습니다"
4-4. Enterprise Analytics API — 조직 수준의 분석
개별 세션의 관측을 넘어, 팀·조직 전체의 Claude Code 사용 패턴을 분석하는 것이 Enterprise Analytics API입니다.
# Enterprise Analytics API 호출 예시
curl -X POST https://api.anthropic.com/v1/enterprise/analytics \
-H "Authorization: Bearer $ADMIN_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"date_range": {
"start": "2026-05-01",
"end": "2026-05-12"
},
"group_by": ["team", "task_type"],
"metrics": [
"total_sessions",
"total_tokens",
"total_cost",
"avg_session_duration",
"success_rate",
"most_used_tools",
"cache_efficiency"
]
}'
응답 예시:
{
"data": [
{
"team": "backend",
"task_type": "code_review",
"total_sessions": 342,
"total_tokens": 12500000,
"total_cost": 45.20,
"avg_session_duration_minutes": 8.3,
"success_rate": 0.94,
"most_used_tools": ["Read", "Grep", "Edit"],
"cache_efficiency": 0.72
},
{
"team": "frontend",
"task_type": "bug_fix",
"total_sessions": 189,
"total_tokens": 8900000,
"total_cost": 32.10,
"avg_session_duration_minutes": 15.7,
"success_rate": 0.87,
"most_used_tools": ["Read", "Bash", "Write"],
"cache_efficiency": 0.58
}
],
"summary": {
"total_cost": 234.50,
"total_sessions": 1847,
"org_cache_savings": 89.30
}
}
이 데이터에서 읽어낼 수 있는 인사이트들입니다:
- 비용 최적화: frontend 팀의 캐시 효율이 58%로 낮습니다. CLAUDE.md에 컨텍스트 관련 지시를 추가하거나, /compact 사용을 권장해 캐시 적중률을 높일 수 있습니다.
- 성공률 개선: bug_fix 태스크의 성공률(87%)이 code_review(94%)보다 낮습니다. 실패 케이스를 분석해 프롬프트를 개선하거나, Subagent 구성을 조정할 수 있습니다.
- 비용 귀속: 팀별, 태스크 유형별 비용을 정확히 추적해 예산 관리와 ROI 측정이 가능합니다.
4-5. 비용·사용량·실패 패턴 추적 실전
운영 수준의 관측을 위해 권장하는 추적 패턴을 정리하겠습니다.
패턴 1: 비용 이상 탐지
# 이동 평균 대비 이상치 탐지
# 지난 7일 평균 대비 200% 초과 시 알림
avg_over_time(
sum(rate(claude_code_api_cost_usd_total[1h]))[7d:1h]
) * 2.0
갑자기 비용이 급증하는 패턴은 보통 무한 루프에 빠진 에이전트, 의도치 않은 대량 작업, 또는 컨텍스트 폭발(compact 미사용)이 원인입니다.
패턴 2: 실패 유형 분류
# Hook에서 실패 유형을 분류하는 패턴
# .claude/hooks/post-tool-use-analytics.sh
#!/bin/bash
TOOL_NAME=$(echo "$CLAUDE_TOOL_NAME")
EXIT_CODE=$(echo "$CLAUDE_TOOL_EXIT_CODE")
if [ "$EXIT_CODE" != "0" ]; then
# OpenTelemetry Collector에 커스텀 메트릭 전송
curl -s -X POST http://otel-collector:4318/v1/metrics \
-H "Content-Type: application/json" \
-d "{
\"resourceMetrics\": [{
\"scopeMetrics\": [{
\"metrics\": [{
\"name\": \"claude_code_tool_failure_detail\",
\"sum\": {
\"dataPoints\": [{
\"attributes\": [
{\"key\": \"tool\", \"value\": {\"stringValue\": \"$TOOL_NAME\"}},
{\"key\": \"exit_code\", \"value\": {\"intValue\": $EXIT_CODE}}
],
\"asInt\": 1
}]
}
}]
}]
}]
}"
fi
패턴 3: 세션 리플레이
모든 세션의 상세 이벤트를 기록해두면, 나중에 문제가 발생했을 때 해당 세션을 “리플레이”하며 원인을 분석할 수 있습니다.
# 세션 이벤트 로그 구조
{
"session_id": "sess_abc123",
"timestamp": "2026-05-12T09:15:23Z",
"events": [
{"type": "prompt", "content": "auth.ts 리팩터링해줘", "tokens": 24},
{"type": "tool_call", "tool": "Read", "target": "src/auth.ts", "duration_ms": 12},
{"type": "thinking", "tokens": 1523},
{"type": "tool_call", "tool": "Edit", "target": "src/auth.ts", "duration_ms": 8},
{"type": "tool_call", "tool": "Bash", "command": "npm test", "exit_code": 1, "duration_ms": 4523},
{"type": "thinking", "tokens": 892},
{"type": "tool_call", "tool": "Edit", "target": "src/auth.ts", "duration_ms": 6},
{"type": "tool_call", "tool": "Bash", "command": "npm test", "exit_code": 0, "duration_ms": 3891},
{"type": "response", "content": "리팩터링 완료...", "tokens": 342}
],
"summary": {
"total_tokens": 18423,
"total_cost": 0.054,
"tool_calls": 5,
"errors": 1,
"duration_seconds": 47
}
}
5. 전체 아키텍처 — 모든 것을 연결하다
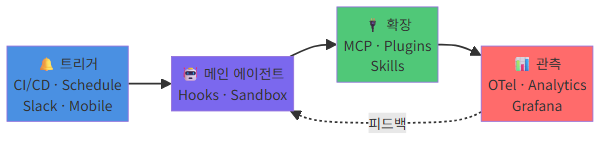
5-1. 24/7 운영급 Claude Code 환경의 전체 그림
지금까지 다룬 모든 요소를 하나의 아키텍처로 통합하면 다음과 같습니다:
┌─────────────────────────────────────────────────────────────────┐
│ 트리거 계층 │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ ┌───────────────┐ │
│ │ CI/CD │ │ Schedule │ │ Slack/ │ │ Mobile / │ │
│ │ Webhook │ │ (cron) │ │ GitHub │ │ Console App │ │
│ └────┬─────┘ └────┬─────┘ └────┬─────┘ └──────┬────────┘ │
│ │ │ │ │ │
│ └─────────────┴──────┬──────┴───────────────┘ │
│ ▼ │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ Dispatch / Remote Control / Channels │ │
│ └──────────────────────┬──────────────────────────────┘ │
└─────────────────────────┼───────────────────────────────────────┘
▼
┌─────────────────────────────────────────────────────────────────┐
│ 에이전트 실행 계층 │
│ ┌──────────────────────────────────────────────────────┐ │
│ │ Main Agent (CLAUDE.md + Memory + Context) │ │
│ │ ┌─────────────┐ ┌─────────────┐ ┌────────────────┐ │ │
│ │ │ Subagent: │ │ Subagent: │ │ Subagent: │ │ │
│ │ │ Reviewer │ │ Tester │ │ Security │ │ │
│ │ └─────────────┘ └─────────────┘ └────────────────┘ │ │
│ └──────────────────────┬───────────────────────────────┘ │
│ │ │
│ ┌──────────────────────┴───────────────────────────────┐ │
│ │ Hooks 계층 │ │
│ │ PreToolUse │ PostToolUse │ SubagentStop │ Stop │ │
│ └──────────────────────┬───────────────────────────────┘ │
│ │ │
│ ┌──────────────────────┴───────────────────────────────┐ │
│ │ 샌드박스 계층 │ │
│ │ PID Namespace │ seccomp-bpf │ FS/Network 격리 │ │
│ └──────────────────────────────────────────────────────┘ │
└─────────────────────────┼───────────────────────────────────────┘
▼
┌─────────────────────────────────────────────────────────────────┐
│ 확장 계층 │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ ┌──────────────┐ │
│ │ MCP │ │ Plugins │ │ Skills │ │ Git / │ │
│ │ Servers │ │ │ │ (SKILL.md)│ │ External API │ │
│ └──────────┘ └──────────┘ └──────────┘ └──────────────┘ │
└─────────────────────────┼───────────────────────────────────────┘
▼
┌─────────────────────────────────────────────────────────────────┐
│ 관측 계층 │
│ ┌─────────────────┐ ┌─────────────────┐ ┌────────────────┐ │
│ │ OpenTelemetry │ │ Enterprise │ │ Audit Logs │ │
│ │ (Traces/Metrics)│ │ Analytics API │ │ │ │
│ └────────┬────────┘ └────────┬────────┘ └───────┬────────┘ │
│ └────────────────────┼────────────────────┘ │
│ ▼ │
│ ┌──────────────────────────────────────────────────────┐ │
│ │ Grafana / Datadog / Custom Dashboard │ │
│ │ → 비용 추적, 에러 분석, 용량 계획, 팀별 사용량 리포트 │ │
│ └──────────────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────────────────┘
5-2. 운영 체크리스트
24/7 운영 환경을 구축할 때 확인해야 할 항목을 정리합니다:
보안:
- API 키·토큰을 환경변수 또는 시크릿 매니저에서 주입하고 있는가?
- 샌드박스 정책이 적절한 수준으로 설정되어 있는가?
- Hooks에서 민감정보 마스킹이 동작하는가?
- 에이전트의 Git 권한이 필요한 레포지토리로 제한되어 있는가?
비용:
- 일/주/월 비용 상한이 설정되어 있는가?
- 프롬프트 캐시 적중률을 모니터링하고 있는가?
- 불필요한 컨텍스트 팽창을 /compact로 관리하고 있는가?
- 서브에이전트별 모델 티어가 적절하게 배분되어 있는가?
신뢰성:
- 실패 시 재시도 정책이 설정되어 있는가?
- 타임아웃이 적절한 값으로 설정되어 있는가?
- 에이전트 무한 루프 방지 장치(/loop의 max-iterations)가 있는가?
- 실패 알림이 적시에 전달되는가?
관측:
- OTel 수집기가 안정적으로 동작하는가?
- 핵심 메트릭에 대한 알림 규칙이 설정되어 있는가?
- 세션 로그가 충분한 기간 보관되는가?
- 비용 이상 탐지가 동작하는가?
6. 실전 시나리오: 소규모 팀의 24/7 운영 구축기
6-1. 시나리오 설정
5명 규모의 스타트업 개발팀이 Claude Code를 팀 인프라로 도입하는 과정을 따라가 보겠습니다. 목표는 명확합니다: 코드 리뷰·테스트·보안 스캔·의존성 관리를 24/7 자동화.
6-2. 단계별 구축
1단계: CI 통합 (Day 1-2)
# .github/workflows/claude-ci.yml
name: Claude Code CI Integration
on:
pull_request:
types: [opened, synchronize, ready_for_review]
jobs:
claude-review:
runs-on: ubuntu-latest
permissions:
contents: read
pull-requests: write
steps:
- uses: actions/checkout@v4
with:
fetch-depth: 0
- uses: anthropic/claude-code-action@v1
with:
api-key: ${{ secrets.ANTHROPIC_API_KEY }}
permissions: plan
task: |
이 PR을 리뷰해줘. 다음을 확인해:
1. 코드 품질과 가독성
2. 잠재적 버그
3. 테스트 커버리지
4. 보안 취약점
결과를 PR 코멘트로 남겨줘.
2단계: Scheduled Tasks 등록 (Day 3-4)
# 보안 스캔 — 매일 새벽 3시
/schedule "nightly-security" --cron "0 3 * * *" --cloud \
--task "npm audit과 Snyk 스캔을 실행하고,
Critical/High 취약점이 있으면 GitHub Issue를 생성해줘"
# 의존성 업데이트 — 매주 월요일 새벽 2시
/schedule "weekly-deps" --cron "0 2 * * 1" --cloud \
--task "outdated 패키지를 확인하고,
minor/patch 업데이트는 자동으로 PR을 만들어줘.
major 업데이트는 이슈로만 등록해줘"
# 코드 품질 리포트 — 매주 금요일 오후 6시
/schedule "weekly-quality" --cron "0 18 * * 5" --cloud \
--task "이번 주의 코드 변경사항을 분석하고,
기술 부채 리포트를 작성해서 팀 Slack #dev에 공유해줘"
3단계: 관측 인프라 구축 (Day 5-7)
# docker-compose.yml — 관측 스택
version: '3.8'
services:
otel-collector:
image: otel/opentelemetry-collector-contrib:latest
ports:
- "4317:4317" # gRPC
- "4318:4318" # HTTP
volumes:
- ./otel-config.yml:/etc/otelcol-contrib/config.yaml
prometheus:
image: prom/prometheus:latest
ports:
- "9090:9090"
volumes:
- ./prometheus.yml:/etc/prometheus/prometheus.yml
grafana:
image: grafana/grafana:latest
ports:
- "3000:3000"
volumes:
- ./grafana/dashboards:/var/lib/grafana/dashboards
- ./grafana/provisioning:/etc/grafana/provisioning
environment:
- GF_SECURITY_ADMIN_PASSWORD=secure-password
6-3. 1개월 후 운영 결과
이 구성을 1개월 운영한 후의 가상 결과를 살펴보겠습니다:
- PR 리뷰 시간: 평균 4시간 → 15분 (자동 리뷰 완료까지)
- 보안 취약점 발견: 월 2건 → 월 8건 (야간 스캔으로 빠른 발견)
- 의존성 업데이트: 분기별 수동 → 주간 자동 (minor/patch)
- 월간 비용: 약 $150 (팀원 1명의 리뷰 시간 절감 가치 대비 충분히 효율적)
- 캐시 적중률: 초기 45% → 최적화 후 72% (CLAUDE.md 개선, /compact 활용)
7. 시리즈 마무리 — Claude Code를 끝까지 써본 소감
7-1. 6편을 관통하는 핵심 원칙
이 시리즈를 통해 Claude Code의 거의 모든 면을 살펴봤습니다. 6편에 걸친 여정에서 반복적으로 등장한 핵심 원칙을 정리합니다:
원칙 1: 점진적 자율성 확대
Plan mode에서 시작해 Default, Auto, 그리고 –dangerously-skip-permissions까지. 에이전트의 자율성은 한 번에 풀어주는 것이 아니라, 안전장치(Hooks, 샌드박스)를 확인하며 단계적으로 확대하는 것이 핵심입니다.
원칙 2: 구조화된 지시
CLAUDE.md, SKILL.md, 그리고 Named Subagents의 시스템 프롬프트까지. “잘 써둔 문서 한 장이 프롬프트 열 번보다 낫다”는 것을 반복적으로 확인했습니다.
원칙 3: 관측 없는 자동화는 도박
에이전트가 자동으로 일을 하게 만드는 것은 쉽습니다. 그것이 제대로 일을 하는지 확인하는 것이 어렵습니다. OTel, 감사 로그, 알림 — 이 관측 인프라 없이 24/7 운영은 눈 감고 운전하는 것과 같습니다.
원칙 4: 다층 방어
보안은 단일 장벽이 아니라 여러 겹의 방어선입니다. 입력 분류기, 권한 모드, Hooks, 샌드박스, 출력 분류기, 감사 로그 — 이 6개 계층이 겹겹이 쌓여야 안심할 수 있습니다.
7-2. 시리즈 전체 로드맵 회고
| 편 | 주제 | 핵심 takeaway |
|---|---|---|
| 1편 | 코어 메커니즘 | 컨텍스트·권한·캐시를 이해하면 절반은 끝난다 |
| 2편 | 슬래시 커맨드 & 세션 | 30+개 커맨드를 외울 필요 없이 5개 카테고리로 분류 |
| 3편 | MCP·플러그인·스킬 | 에이전트의 손발을 늘리는 확장 생태계 |
| 4편(상) | Hooks | 에이전트에 브레이크를 달아 안전하게 자동화 |
| 4편(하) | Subagents | 복잡한 작업은 역할 분리로 해결 |
| 5편 | 원격·클라우드·관측 | 터미널을 벗어나 24/7 운영급으로 격상 |
7-3. 다음 단계를 위한 제안
이 시리즈를 읽은 여러분이 바로 실천할 수 있는 로드맵입니다:
Week 1: 기반 다지기
- CLAUDE.md를 프로젝트에 추가하고, 코딩 컨벤션·아키텍처 개요를 기록
- Plan mode로 일주일간 사용하며 에이전트의 행동 패턴을 파악
- /compact, /effort 등 기본 커맨드에 익숙해지기
Week 2: 확장하기
- GitHub MCP 서버를 연결해 PR·이슈 자동화 시작
- 자주 쓰는 워크플로우를 SKILL.md로 문서화
- Default mode로 전환하며 자율성 한 단계 확대
Week 3: 자동화하기
- CI에 Claude Code Action 추가 (PR 자동 리뷰)
- Hooks로 커밋 메시지 검증, 보안 스캔 자동 삽입
- Subagent 구성으로 복잡한 태스크 분업 시작
Week 4: 운영하기
- OpenTelemetry 연동으로 사용량·비용 추적 시작
- Scheduled Tasks로 야간 자동화 작업 등록
- Grafana 대시보드로 팀 전체의 에이전트 활용 현황 가시화
7-4. 마치며
Claude Code를 “끝까지 써보기”라는 제목으로 시작한 이 여정을 마칩니다. 처음 터미널에서 claude 명령을 실행했을 때의 단순한 대화형 코딩 어시스턴트가, 이제는 CI/CD 파이프라인을 타고, 샌드박스 안에서 안전하게 코드를 실행하며, Grafana 대시보드에서 실시간으로 관측되는 24/7 운영급 시스템으로 변모했습니다.
물론, 이 모든 기능을 한꺼번에 도입할 필요는 없습니다. 중요한 것은 Claude Code가 “어디까지 갈 수 있는지”를 아는 것입니다. 그 지도가 있으면, 필요한 시점에 필요한 기능을 꺼내 쓸 수 있습니다. 이 시리즈가 그 지도 역할을 했기를 바랍니다.
읽어주셔서 감사합니다. 여러분의 Claude Code 여정에 이 시리즈가 유용한 가이드가 되었길 바랍니다.
◀ 이전 5화 (다음 차수는 아직 게시되지 않았습니다)
참고 자료
- OpenTelemetry 공식 문서 — 분산 추적·메트릭·로그 수집을 위한 오픈소스 관측 프레임워크의 공식 가이드
- Wikipedia: Observability (software) — 소프트웨어 시스템 관측 가능성의 개념과 구성 요소를 정리한 백과사전 문서

