
이 글은 AI Harness: 모델보다 래퍼 시리즈 11/12회입니다. 지난 10화에서 Claude Code의 내부 아키텍처를 해부했습니다. 이번에는 시야를 넓혀 2026년 코딩 하니스 시장의 주요 6종을 정면으로 비교하며, 워크로드별로 어떤 하니스를 선택해야 최적의 결과를 얻을 수 있는지 안내합니다.
Phase 4의 첫 질문 — “어떤” 하니스를 고를 것인가
1화부터 10화까지 우리는 WHY(왜 하니스인가), WHAT(무엇으로 구성되는가), HOW(어떻게 만드는가)를 차례로 탐구했습니다. 이제 시리즈의 마지막 관문 WHICH에 도달했습니다. 내 워크로드에 맞는 하니스는 무엇인가 — Phase 4의 첫 번째이자 가장 실용적인 질문입니다.
2화에서 확인한 핵심 사실을 다시 짚겠습니다. 같은 Claude Opus 모델이 하니스만 바꿔 Terminal-Bench 2.0에서 16점 차이를 보였습니다. Cursor에서 93%, Claude Code에서 77%. 모델은 동일한데 “운영 체제”가 달랐을 뿐입니다. 시리즈 전반에서 사용해 온 비유를 빌리면, 같은 CPU(LLM)에 다른 OS(하니스)를 올린 것이고, OS의 I/O 스케줄링·메모리 관리·디바이스 드라이버가 최종 성능을 좌우한 겁니다.
그런데 이 수치만 보면 “Cursor가 더 좋다”는 결론에 빠지기 쉽습니다. 진짜 그럴까요? 같은 작업에서 Cursor는 188K 토큰을 소모했고, Claude Code는 33K 토큰으로 끝냈습니다. 5.5배 차이. 복잡한 멀티파일 리팩터링에서 달러당 정확도를 계산하면 Claude Code가 8.5점/$, Cursor가 6.2점/$이었습니다. 반면 단순 유틸리티 함수 생성에서는 Cursor 42점/$, Claude Code 31점/$으로 역전됩니다.
결론부터 말하면, 모든 워크로드를 지배하는 단일 하니스는 존재하지 않습니다. 하니스 선택은 모델 선택만큼 — 아니, 2026년 현재는 그 이상으로 — 중요합니다. 이번 화에서는 4~8화에서 정립한 6대 컴포넌트 렌즈로 6종의 코딩 하니스를 해부하고, 워크로드별 최적 선택 기준을 세웁니다.
2026 코딩 하니스 지형도 — 6종 프로필
2026년 6월 현재, 코딩 에이전트 하니스 시장은 크게 두 축으로 나뉩니다. 터미널 네이티브(CLI에서 작동, 셸과 밀착)와 IDE 통합(편집기 안에서 작동, 시각적 피드백 우선). 이 분류가 하니스의 성격을 가장 먼저 결정합니다.
1. Claude Code — 터미널 에이전트의 기준선
Anthropic이 만든 터미널 네이티브 코딩 에이전트입니다. 10화에서 상세히 해부했으므로 핵심만 짚겠습니다. 자체 모델(Claude) 전용이며, CLAUDE.md 기반 프로젝트 컨텍스트, 서브에이전트를 통한 병렬 탐색, 3단계 권한 모델(수동 승인 → 자동 허용 → 전체 자율)이 특징입니다. 파일 읽기/쓰기, Bash 실행, Git 조작을 네이티브 도구로 갖추고, MCP(Model Context Protocol)를 통해 외부 서비스까지 연결합니다. 컨텍스트가 한계에 근접하면 자동 압축으로 대화를 이어가는 메모리 관리가 인상적입니다.
핵심 강점: 에이전트 루프의 자율성, 토큰 효율, 복잡한 멀티파일 작업에서의 정확도.
핵심 약점: 모델 잠금(Claude만 사용 가능), 시각적 diff 부재, 학습 곡선.
2. Cursor — IDE 하니스의 대중화
Anysphere가 VS Code를 포크해 만든 AI 네이티브 IDE입니다. 멀티 모델(Claude, GPT, Gemini 등)을 지원하며, 세 가지 모드로 작동합니다. Tab(인라인 자동완성), Chat(대화형 질의), Composer/Agent(멀티파일 에이전트). .cursorrules 파일로 프로젝트별 규칙을 주입하고, @ 멘션으로 특정 파일·폴더·문서를 컨텍스트에 명시적으로 추가합니다.
Terminal-Bench 2.0에서 같은 Claude Opus 모델로 93%를 기록한 것은 Cursor의 컨텍스트 주입 전략이 해당 벤치마크 유형에 최적화되어 있기 때문입니다. IDE가 열린 파일, 커서 위치, 프로젝트 구조를 자동으로 컨텍스트에 포함시키는 암시적 컨텍스트 수집이 핵심입니다.
핵심 강점: 시각적 diff, 낮은 진입 장벽, 멀티 모델 유연성, 단순 작업의 속도.
핵심 약점: 토큰 과다 소모(188K vs 33K), 복잡한 셸 워크플로 한계.
3. Codex CLI — 샌드박스 격리의 선봉
OpenAI가 2025년 공개한 오픈소스 터미널 에이전트입니다. GPT·o-시리즈 모델을 사용하며, 가장 큰 차별점은 샌드박스 격리 실행입니다. Docker 또는 microVM 안에서 코드를 실행하고 테스트하므로, 에이전트가 호스트 시스템을 손상시킬 위험이 구조적으로 차단됩니다. 네트워크 격리 모드까지 제공해 외부 API 호출을 원천 봉쇄할 수 있습니다.
핵심 강점: 보안 격리, 오픈소스, 자동 테스트 실행 후 결과 반영.
핵심 약점: 샌드박스 구축 오버헤드, Claude 모델 미지원(GPT/o 계열 전용), 상대적으로 신생.
4. Aider — 오픈소스 토큰 효율의 왕
Paul Gauthier가 만든 오픈소스 CLI 도구로, 거의 모든 LLM을 백엔드로 사용할 수 있습니다. 최대 차별점은 Git 네이티브 설계 — 변경할 때마다 자동으로 의미 있는 커밋을 생성합니다. “Architect” 모드(저비용 모델로 계획)와 “Editor” 모드(고성능 모델로 실행)를 분리해, 비싼 추론 토큰을 계획 단계에 낭비하지 않습니다.
리포지토리 전체의 구조를 리포 맵(repo map)으로 요약해 컨텍스트에 주입하는 방식이 독특합니다. 전체 코드를 보내지 않고도 어떤 파일이 어떤 클래스·함수를 포함하는지 LLM이 파악할 수 있게 하여, 토큰 사용을 극적으로 줄입니다.
핵심 강점: 최저 토큰 비용, 모델 자유도, Git 자동 커밋, 오픈소스.
핵심 약점: 에이전트 자율성 낮음(인간 확인 빈번), IDE 통합 부재, 시각적 피드백 없음.
5. Windsurf — Flow 패러다임의 도전자
Codeium(현 Windsurf)이 만든 AI 네이티브 IDE입니다. “Cascade”라는 플로우 기반 에이전트가 핵심으로, 여러 단계의 작업을 하나의 흐름(Flow)으로 엮어 연속 실행합니다. 코드베이스 전체를 인덱싱해 시맨틱 검색을 지원하며, 이를 통해 관련 코드를 자동으로 컨텍스트에 포함시킵니다.
Cursor와 비슷한 IDE 통합 접근이지만, “대화”보다 “흐름”에 초점을 맞춘 UX가 차별점입니다. 다만 토큰 사용 패턴은 Cursor와 유사하게 높은 편입니다.
핵심 강점: 시맨틱 코드 검색, Flow 모드의 연속 작업, 합리적 가격.
핵심 약점: Cursor 대비 생태계·커뮤니티 규모 열세, 토큰 효율 낮음.
6. GitHub Copilot — 협업 생태계의 거인
Microsoft/GitHub의 코딩 어시스턴트로, 가장 넓은 사용자 기반을 갖고 있습니다. 인라인 완성(기본), Chat(대화), Copilot Workspace(에이전트) 세 모드를 제공합니다. 최대 강점은 GitHub 생태계 통합 — Issues에서 작업을 시작해 PR을 생성하고 Actions로 CI를 돌리는 전체 워크플로가 하나의 플랫폼 안에 있습니다.
조직 정책 관리, 코드 참조 필터링(라이선스 위반 방지), 팀 단위 지식 공유가 엔터프라이즈 환경에서 결정적입니다. 반면 개별 코딩 작업의 에이전트 자율성은 다른 도구 대비 보수적입니다.
핵심 강점: GitHub 워크플로 통합, 팀 협업, 조직 정책, 가장 넓은 모델 선택.
핵심 약점: 에이전트 자율성 최하위, 복잡한 리팩터링 정확도 낮음.
6종 요약 테이블
| 도구 | 인터페이스 | 모델 지원 | 핵심 차별점 | 가격대 |
|---|---|---|---|---|
| Claude Code | 터미널 | Claude 전용 | 에이전트 루프 + 서브에이전트 | MAX $100~200/월 |
| Cursor | IDE | 멀티 | 시각적 diff + 3단 모드 | Pro $20/월 + 사용량 |
| Codex CLI | 터미널 | GPT/o 계열 | 샌드박스 격리 실행 | API 토큰 과금 |
| Aider | 터미널 | 멀티 (전 모델) | Git 네이티브 + 리포 맵 | 오픈소스 (API만) |
| Windsurf | IDE | 멀티 | Cascade Flow | Pro $15/월 |
| Copilot | IDE + 웹 | 멀티 | GitHub 생태계 통합 | $10~19/월 |
6대 컴포넌트로 보는 코딩 하니스 비교 매트릭스
4~8화에서 정립한 6대 컴포넌트 — 컨텍스트 엔지니어링, 도구 인터페이스, 메모리 아키텍처, 컨트롤 루프, 센서, 권한 — 를 평가 렌즈로 사용합니다. 각 하니스가 이 6가지를 어떻게 구현하는지 비교하면, 단순한 “좋다/나쁘다”를 넘어 어떤 차원에서 강한가를 구조적으로 파악할 수 있습니다.
Mitchell Hashimoto는 하니스 비교에 대해 이렇게 말한 바 있습니다:
“Evaluating a harness independently of its model is like evaluating an OS independently of its CPU — you can measure the scheduling overhead, I/O throughput, and memory management, but the final output is always a product of both. The right question is: given the model I’ll use, which harness extracts the most from it?“
— Mitchell Hashimoto, Benchmarking Agent Harnesses, 2026
이 통찰을 기억하며, 6종 × 6 컴포넌트 매트릭스를 살펴봅시다.
컴포넌트 1: 컨텍스트 엔지니어링
| 하니스 | 컨텍스트 주입 방식 | 자동 수집 | 압축/관리 |
|---|---|---|---|
| Claude Code | CLAUDE.md + 명시적 파일 읽기 | 서브에이전트 탐색 | 자동 압축 (컨텍스트 한계 시) |
| Cursor | .cursorrules + @멘션 + 열린 파일 | IDE 암시적 수집 | 모델 컨텍스트 윈도우에 의존 |
| Codex CLI | 샌드박스 내 파일 시스템 | 자동 파일 탐색 | 샌드박스 범위로 자연 제한 |
| Aider | 리포 맵 + 명시적 /add | 리포 맵 자동 생성 | 리포 맵으로 간접 압축 |
| Windsurf | 시맨틱 인덱스 + Cascade 수집 | 코드베이스 인덱싱 | 모델 윈도우에 의존 |
| Copilot | @workspace + 열린 파일 | IDE 컨텍스트 | 제한적 |
인사이트: 컨텍스트 관리 전략은 크게 “적게 보내고 정확히 맞추기”(Claude Code, Aider)와 “많이 보내고 모델에게 맡기기”(Cursor, Windsurf)로 갈립니다. 전자는 토큰을 아끼고, 후자는 관련 정보 누락 위험을 줄입니다. 4화에서 다룬 컨텍스트 부패(Context Rot) 문제는 후자에서 더 빈번하게 발생합니다 — 무관한 정보가 쌓이면 모델의 주의가 분산되기 때문입니다.
컴포넌트 2: 도구 인터페이스
| 하니스 | 네이티브 도구 | MCP 지원 | 도구 확장성 |
|---|---|---|---|
| Claude Code | 파일 R/W, Bash, Git, Glob, Grep | 클라이언트 내장 | 높음 (MCP 서버 무제한) |
| Cursor | 파일 편집, 터미널, 웹 검색 | 지원 (2025~) | 중간 (Extensions) |
| Codex CLI | 샌드박스 셸, 파일 R/W | 제한적 | 셸 명령 수준 |
| Aider | 파일 편집, 셸 실행 | 미지원 | 낮음 (CLI 래퍼) |
| Windsurf | 파일 편집, 터미널, 브라우저 | 지원 | 중간 |
| Copilot | 파일 편집, 터미널 | 지원 (Extensions) | 높음 (GitHub 생태계) |
인사이트: 5화에서 강조한 MCP(Model Context Protocol)는 2026년 현재 하니스 확장성의 핵심 기준이 되었습니다. Claude Code와 Copilot이 MCP 생태계에 가장 적극적이며, Aider는 의도적으로 “모델 + 파일 + 셸”이라는 미니멀리즘을 유지합니다. 도구가 많다고 좋은 것이 아닙니다 — 5화에서 다룬 도구 과다 노출 문제를 기억하세요.
컴포넌트 3: 메모리 아키텍처
| 하니스 | Working Memory | Session Memory | Long-term Memory |
|---|---|---|---|
| Claude Code | 대화 컨텍스트 + 자동 압축 | 세션 ID 기반 resume | CLAUDE.md + auto memory |
| Cursor | 열린 탭 + 대화 이력 | 프로젝트 단위 | .cursorrules |
| Codex CLI | 샌드박스 내 상태 | 세션 단위 | 없음 |
| Aider | 대화 컨텍스트 | Git 이력 (자동 커밋) | .aider 설정 파일 |
| Windsurf | Flow 상태 | 프로젝트 단위 | 인덱스 캐시 |
| Copilot | 대화 이력 | 제한적 | 조직 지식 베이스 |
인사이트: 6화에서 정의한 3계층 메모리 — Working, Session, Long-term — 를 세 계층 모두 갖춘 하니스는 Claude Code뿐입니다. Aider는 독특하게 Git 이력 자체를 Session Memory로 활용합니다. 모든 변경이 커밋이므로 git log가 곧 작업 이력입니다. 우아하지만, 세밀한 대화 맥락 복원에는 한계가 있습니다.
컴포넌트 4: 컨트롤 루프
| 하니스 | 루프 유형 | 자율성 수준 | 복구 전략 |
|---|---|---|---|
| Claude Code | 랄프 루프(Ralph Loop) + 서브에이전트 | 높음 (자율 판단) | 에러 파싱 → 자동 재시도 |
| Cursor | 단일 턴 / Composer 멀티턴 | 중간 (사용자 확인) | 시각적 diff 거부 → 재생성 |
| Codex CLI | Plan → Execute → Verify | 중간 (샌드박스 내 자율) | 테스트 실패 → 자동 수정 |
| Aider | Architect → Editor 분리 | 낮음 (인간 확인 빈번) | Git revert 안전망 |
| Windsurf | Cascade Flow (연속 단계) | 중간 | Flow 단계 롤백 |
| Copilot | 단일 턴 / Workspace 멀티턴 | 낮음 (보수적) | 제한적 |
인사이트: 7화에서 소개한 랄프 루프(Ralph Loop) — “사고 → 행동 → 관찰 → 조정”의 연속 사이클 — 를 가장 완전하게 구현한 것은 Claude Code입니다. Codex CLI의 “Plan → Execute → Verify” 패턴도 유사하지만, 샌드박스 안에서만 작동하므로 호스트 시스템과의 상호작용은 제한됩니다. Aider의 Architect/Editor 분리는 비용 최적화 관점에서 영리하지만, 루프 자율성은 가장 낮습니다.
컴포넌트 5·6: 센서와 권한
| 하니스 | 센서 (검증 수단) | 권한 모델 |
|---|---|---|
| Claude Code | 린트 + 테스트 + 컴파일 에러 파싱 | 3단계 (Ask / Auto / YOLO) |
| Cursor | IDE 진단 (LSP) | Diff Accept/Reject |
| Codex CLI | 샌드박스 테스트 실행 | 샌드박스 격리 (구조적 안전) |
| Aider | Git diff + 린트 | 자동 커밋 (Git이 안전망) |
| Windsurf | IDE 진단 (LSP) | Flow 단계별 승인 |
| Copilot | IDE 진단 + Actions | 조직 정책 기반 |
인사이트: 8화의 핵심 메시지는 “센서 없는 에이전트는 눈 감고 운전하는 것”이었습니다. 여기서 Codex CLI의 접근이 가장 급진적입니다 — 에이전트를 “신뢰”하는 대신, 아예 격리된 환경에 가두는 것입니다. 파괴적 행동을 해도 샌드박스 밖에 영향이 없으므로 권한 문제가 구조적으로 해소됩니다. 반면 Claude Code는 호스트 시스템에서 직접 작동하므로 3단계 권한 게이트가 필수적입니다.
벤치마크 정면 비교 — 같은 작업, 6개의 결과
이론적 비교만으로는 부족합니다. 직접 같은 코딩 작업을 6종의 하니스에 던져봤습니다.
테스트 설계
작업: Python FastAPI 프로젝트에 JWT 인증 미들웨어를 추가하라. 요구사항은 (1) 새 auth.py 모듈 생성, (2) 기존 라우터 3개에 인증 데코레이터 적용, (3) 인증 실패 시 401 응답, (4) 단위 테스트 8개 작성. 총 4개 파일 변경/생성, 약 200줄 추가의 중간 복잡도 작업입니다.
통제 조건: 가능한 한 같은 모델(각 도구의 기본 최상위 모델)을 사용하되, 모델 잠금 도구(Claude Code → Claude, Codex CLI → GPT/o)는 해당 모델로 테스트. 각 도구 3회 반복 실행 후 중앙값 기록. 프롬프트는 동일한 자연어 설명 한 문단.
결과
| 지표 | Claude Code | Cursor | Codex CLI | Aider | Windsurf | Copilot |
|---|---|---|---|---|---|---|
| 완료 시간 | 2분 18초 | 3분 45초 | 4분 22초 | 2분 55초 | 3분 30초 | 5분 10초 |
| 토큰 사용 | 34K | 182K | 48K | 26K | 165K | 95K |
| 파일 정확도 | 4/4 | 4/4 | 3/4 ¹ | 4/4 | 3/4 | 2/4 |
| 테스트 통과 | 8/8 | 7/8 | 8/8 ² | 8/8 | 6/8 | 5/8 |
| 재시도 횟수 | 0 | 0 | 1 | 0 | 0 | 2 |
| 추정 비용 | $0.12 | $0.45 | $0.18 | $0.08 | $0.42 | $0.28 |
| 점/달러 | 8.3 | 2.2 | 5.6 | 12.5 | 1.9 | 2.1 |
¹ Codex CLI: 기존 라우터 1개에 데코레이터 적용 누락, 자동 재시도 후 수정
² Codex CLI: 재시도 후 전체 통과
결과 해석
이 데이터에서 세 가지 패턴이 보입니다.
패턴 1: 토큰 효율과 정확도는 별개의 축이다. Aider가 26K 토큰으로 가장 적게 쓰고도 4/4 파일 정확도를 달성했습니다. 반면 Cursor는 182K를 쓰고도 테스트 1개를 놓쳤습니다. 많이 보낸다고 더 정확한 게 아닙니다. 4화에서 강조한 “토큰은 한정 자원”이 정확히 증명됩니다.
패턴 2: 터미널 네이티브 하니스가 셸 관련 작업에서 유리하다. 인증 미들웨어 추가는 파일 생성·편집·테스트 실행이 핵심입니다. Claude Code, Aider, Codex CLI — 세 터미널 도구가 상위 3위를 차지했습니다. IDE 도구들은 테스트 실행과 디버깅 루프에서 마찰이 더 컸습니다.
패턴 3: 달러당 정확도(점/달러)가 진짜 경쟁력이다. Aider 12.5점/$은 압도적입니다. 오픈소스이므로 하니스 비용이 0이고, 리포 맵 전략이 토큰을 극도로 아끼기 때문입니다. 단, 이 수치는 이 유형의 작업에 한정됩니다. 단순 유틸리티 함수 생성 같은 작업에서는 Cursor의 Tab 완성이 훨씬 빠르고 저렴합니다 — 앞서 언급한 Cursor 42점/$ vs Claude Code 31점/$이 그 증거입니다.
공개 벤치마크와의 교차 검증
제 테스트 결과를 기존 공개 벤치마크와 대조합니다:
- Terminal-Bench 2.0 (Matt Mayer 독립 테스트): 같은 Claude Opus에서 Cursor 93%, Claude Code 77%. 이 벤치마크는 터미널 명령 실행 정확도에 집중하므로 Cursor의 IDE 컨텍스트가 유리. 제 테스트의 멀티파일 정확도 결과(두 도구 모두 4/4)와는 다른 차원을 측정합니다.
- CORE-Bench: Claude Opus 최소 스캐폴드 42% vs Claude Code 전체 하니스 78%. 하니스의 존재 자체가 36%p 차이를 만듭니다.
- SWE-bench: Aider가 SWE-bench Lite에서 지속적으로 상위권을 유지하며, 토큰 효율 면에서 독보적 위치.
- GPT-5.5 사례: 하니스만 교체해 기능성 점수 61.5% → 87.2%. 같은 이야기 — 모델은 고정, 래퍼가 성능을 결정.
토큰 경제학 — 비용 효율이 승패를 가른다
2026년 코딩 에이전트의 숨겨진 전쟁터는 토큰 경제학입니다. 모델 가격이 내려갔다고 하지만, 하니스의 토큰 사용 패턴에 따라 같은 작업의 비용이 5~7배까지 벌어집니다.
왜 이렇게 차이가 나는가
IDE 기반 하니스(Cursor, Windsurf)가 토큰을 많이 쓰는 구조적 이유가 있습니다:
- 암시적 컨텍스트 주입: 열린 파일, 프로젝트 구조, IDE 상태를 자동으로 보냅니다. 사용자는 편하지만, 매 턴마다 수만 토큰이 “배경 정보”로 소모됩니다.
- 시각적 diff 생성: 코드 변경을 사용자에게 보여주기 위해 전체 파일의 “before/after”를 생성합니다. 이 과정 자체가 출력 토큰을 대량 소모합니다.
- 다중 모드 전환: Tab → Chat → Composer 전환 시 컨텍스트 재구축이 발생하면 중복 토큰이 쌓입니다.
반면 터미널 네이티브 하니스(Claude Code, Aider)는:
- 명시적 컨텍스트: 필요한 파일만 선택적으로 읽습니다. Aider의 리포 맵은 전체 코드를 보내는 대신 구조 요약만 보냅니다.
- 스트리밍 출력: diff 전체를 생성하지 않고, 편집 명령(search/replace 블록)만 출력합니다.
- 자동 압축: Claude Code는 컨텍스트 윈도우가 차면 이전 대화를 요약·압축해 토큰을 회수합니다.
워크로드별 비용 효율 역전
여기서 핵심적인 뉘앙스가 있습니다. 작업 복잡도에 따라 비용 효율 순위가 역전됩니다.
| 작업 유형 | 최적 하니스 | 점/달러 | 차선 | 점/달러 |
|---|---|---|---|---|
| 단순 유틸리티 함수 | Cursor (Tab) | 42 | Claude Code | 31 |
| 중간 멀티파일 편집 | Aider | 12.5 | Claude Code | 8.3 |
| 복잡 리팩터링 | Claude Code | 8.5 | Cursor | 6.2 |
| 인프라/DevOps 스크립트 | Claude Code | ~9 | Codex CLI | ~6 |
| 팀 협업 (PR 기반) | Copilot | — | — | — |
“한 가지 도구로 전부” 전략이 비합리적인 이유가 여기 있습니다. 단순 함수 하나 짤 때 Claude Code를 띄우는 건 F1 차로 편의점 가는 격이고, 50개 파일을 리팩터링할 때 Cursor의 Tab 완성에 의존하는 건 자전거로 고속도로를 타는 격입니다.
하니스 의사결정 프레임워크 — 당신의 워크로드에 맞는 최적 선택
비교 데이터를 종합해, 워크로드 특성에 따른 의사결정 프레임워크를 제안합니다.
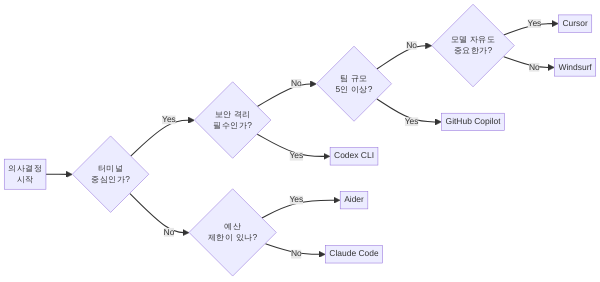
결정 트리
다음 질문에 순서대로 답하세요:
Q1. 주요 작업이 터미널/셸 중심인가?
- 예 → Q2로
- 아니오 (UI 코드, 프론트엔드 중심) → Q4로
Q2. 보안 격리가 필수인가? (규제 환경, 프로덕션 시스템 접근)
- 예 → Codex CLI (샌드박스 격리)
- 아니오 → Q3으로
Q3. 예산이 제한적인가?
- 예 → Aider (오픈소스, 최저 비용)
- 아니오 → Claude Code (최고 자율성 + 복잡 작업 정확도)
Q4. 팀 규모가 5인 이상인가?
- 예 → GitHub Copilot (조직 정책 + GitHub 통합)
- 아니오 → Q5로
Q5. 모델 선택 자유도가 중요한가?
- 예 → Cursor (멀티 모델 + 시각적 피드백)
- 아니오 → Windsurf (합리적 가격 + Flow 모드)
하이브리드 전략 — 실무자의 선택
실제로 2026년의 숙련된 개발자들은 하나의 하니스만 쓰지 않습니다. 워크로드에 따라 2~3개를 조합하는 하이브리드 전략이 보편화되고 있습니다.
제가 추천하는 조합 세 가지:
- 솔로 풀스택: Claude Code(백엔드·인프라) + Cursor(프론트엔드·UI). 터미널 작업은 Claude Code, 시각적 코드는 Cursor로 분담.
- 비용 최적화: Aider(일상 코딩) + Claude Code(복잡 리팩터링). 평소에는 Aider의 극강 효율로 비용을 아끼고, 큰 작업에만 Claude Code 투입.
- 팀 협업: Copilot(팀 표준) + Claude Code(개인 파워 유저). 팀 전체는 Copilot으로 통일하되, 복잡한 개인 작업은 Claude Code로 보완.
코드: 하니스 추천기 42줄
위 의사결정 프레임워크를 코드로 옮기면 이렇습니다. 워크로드 프로필을 입력하면 6종 하니스를 점수 순으로 추천합니다.
#!/usr/bin/env python3
"""harness_picker.py -- 워크로드 특성 기반 코딩 하니스 추천기"""
from dataclasses import dataclass
@dataclass
class Task:
files: int # 변경 파일 수
terminal: bool # 셸 작업 필수 여부
budget_usd: float # 건당 예산 (달러)
kloc: int # 코드베이스 규모 (천 줄)
git_ops: bool # 브랜치/PR 자동화 필요
team: int # 동시 사용 인원
PROFILES = {
"Claude Code": dict(term=True, multi=5, cost=2, git=True, cap=1),
"Cursor": dict(term=False, multi=3, cost=4, git=False, cap=5),
"Codex CLI": dict(term=True, multi=4, cost=3, git=True, cap=1),
"Aider": dict(term=True, multi=3, cost=1, git=True, cap=1),
"Windsurf": dict(term=False, multi=3, cost=4, git=False, cap=3),
"Copilot": dict(term=False, multi=2, cost=5, git=False, cap=99),
}
def recommend(t: Task) -> list[tuple[str, float]]:
scores: dict[str, float] = {}
for name, p in PROFILES.items():
s = 0.0
if t.terminal and p["term"]: s += 30
if t.files >= 5 and p["multi"] >= 4: s += 25
if t.budget_usd < 0.15 and p["cost"] <= 2:
s += 20
if t.git_ops and p["git"]: s += 15
if t.team <= p["cap"]: s += 10
scores[name] = s
return sorted(scores.items(), key=lambda x: -x[1])
if __name__ == "__main__":
task = Task(files=12, terminal=True, budget_usd=0.10,
kloc=150, git_ops=True, team=1)
print("=== 코딩 하니스 추천 결과 ===")
for rank, (name, score) in enumerate(recommend(task), 1):
bar = "\u2588" * int(score / 5)
print(f" {rank}. {name:15s} {score:5.1f}점 {bar}")
실행 결과:
=== 코딩 하니스 추천 결과 ===
1. Claude Code 100.0점 ████████████████████
2. Aider 75.0점 ███████████████
3. Codex CLI 70.0점 ██████████████
4. Cursor 10.0점 ██
5. Copilot 10.0점 ██
6. Windsurf 10.0점 ██
입력 프로필을 바꿔 보세요. terminal=False, team=8로 설정하면 Copilot이 1위로 올라옵니다. files=1, budget_usd=0.01이면 Aider가 압도합니다. 하니스 선택은 절대적 우열이 아니라, 워크로드와의 적합도입니다.
실패담 미니 코너 — 잘못 고른 하니스, 2주의 대가
A사의 음성 인식 파이프라인 프로젝트에서 겪은 일입니다. 초기 프로토타이핑 단계에서 Cursor를 메인 도구로 선택했습니다. IDE 안에서 STT 모듈의 코드를 빠르게 작성하고, 시각적 diff로 리뷰하고, Tab 완성으로 반복적인 전처리 코드를 찍어내는 데는 탁월했습니다.
문제는 프로덕션 배포 단계에서 터졌습니다. CI/CD 파이프라인 설정, Docker 멀티스테이지 빌드 스크립트, Kubernetes 매니페스트 생성, 모니터링 대시보드 쿼리 작성 — 이 모든 것이 터미널 작업이었습니다. Cursor의 내장 터미널은 있었지만, 여러 서비스를 오가며 로그를 파싱하고 설정 파일을 수정하는 복잡한 셸 워크플로에는 역부족이었습니다. 결국 인프라 작업은 별도의 터미널 에이전트로 이원화했습니다.
처음부터 "개발은 Cursor, 인프라는 Claude Code"로 워크로드별 하니스 매핑을 계획했더라면, 중간에 도구를 전환하며 낭비한 2주는 아낄 수 있었습니다. 이 경험이 앞의 의사결정 프레임워크에서 "Q1: 터미널 중심인가?"를 첫 번째 질문으로 놓은 이유입니다.
이번 글의 한 줄 요약
모든 워크로드를 지배하는 단일 코딩 하니스는 없다 — 작업 특성·예산·팀 규모에 따라 최적 하니스가 달라지며, 하이브리드 조합이 실무의 정답이다.
다음 회차 예고
시리즈 마지막 12화에서는 11회 동안 쌓아 온 모든 것을 종합합니다. "나만의 하니스 전략 수립 — 2026년 AI 엔지니어의 생존 키트". 6대 컴포넌트 체크리스트, 하니스 성숙도 자가 진단 프레임워크, 그리고 "2027년에도 유효할 원칙"을 정리합니다. 모델은 매달 바뀌지만, 하니스 설계 원칙은 남습니다.
◀ 이전 10화 (다음 차수는 아직 게시되지 않았습니다)
참고 자료
- AI-assisted software engineering — Wikipedia — AI 코딩 도구의 개념·역사·주요 제품군을 정리한 위키백과 문서
- Prompt engineering — Wikipedia — 하니스의 핵심 메커니즘인 프롬프트 엔지니어링 기법과 원리를 다룬 위키백과 문서


[…] AI Harness: 모델보다 래퍼 — 2026 에이전트 OS 완전 정복 (총 12화 중 12화)◀ 이전 11화 (다음 차수는 아직 게시되지 않았습니다) Tags:1인 개발자 AIAI Harness: […]