
회의가 끝나면 으레 따라오는 숙제가 있습니다. 바로 회의록 정리입니다. 1시간짜리 회의 내용을 텍스트로 옮기려면 보통 2~3시간은 족히 걸리고, 강의 녹음을 다시 듣고 필기하는 것도 만만치 않죠. 그런데 2026년 현재, AI 음성 인식 기술은 놀라운 수준까지 발전했습니다. 특히 OpenAI가 공개한 Whisper AI 모델은 무료로 사용할 수 있으면서도 한국어 인식 정확도가 매우 높아, 개인 PC에서 바로 돌릴 수 있는 실용적인 도구가 되었습니다.
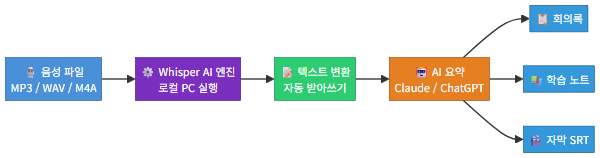
이 글에서는 Whisper AI를 내 컴퓨터에 직접 설치하고, 회의 녹음·강의·인터뷰 음성 파일을 텍스트로 변환한 뒤, AI 요약까지 자동화하는 전체 과정을 단계별로 안내합니다. 클라우드에 음성 파일을 올리지 않아도 되니 보안 걱정도 없고, 비용도 들지 않습니다.
Whisper AI란 무엇인가 – 로컬에서 돌리는 음성 인식의 혁신
Whisper 모델의 특징과 장점
Whisper는 OpenAI가 2022년에 오픈소스로 공개한 범용 음성 인식 모델입니다. 68만 시간 분량의 다국어 음성 데이터로 학습되었으며, 한국어를 포함한 99개 언어를 지원합니다. 가장 큰 장점은 세 가지입니다.
- 무료·오픈소스: 상업적 용도를 포함해 누구나 자유롭게 사용할 수 있습니다. API 비용이 전혀 들지 않습니다.
- 로컬 실행: 인터넷 연결 없이 내 PC에서 바로 실행됩니다. 회의 녹음이나 사내 기밀 내용이 외부 서버로 전송될 걱정이 없습니다.
- 높은 한국어 정확도: 2024~2025년 커뮤니티 최적화와 fine-tuning 모델 덕분에 한국어 인식률이 크게 향상되었습니다. 일반 대화 기준 95% 이상의 정확도를 보여줍니다.
Whisper 모델 크기별 비교
Whisper는 용도와 PC 사양에 따라 선택할 수 있도록 여러 크기의 모델을 제공합니다. 각 모델의 차이를 이해하면 자신의 환경에 맞는 최적의 선택을 할 수 있습니다.
- tiny (39M 파라미터): 가장 가벼운 모델입니다. VRAM 1GB 정도면 충분하고 변환 속도가 매우 빠릅니다. 다만 한국어 정확도가 낮아 영어 메모 수준에만 적합합니다.
- base (74M): tiny보다 정확도가 소폭 개선되었지만, 역시 한국어에는 부족합니다. 빠른 테스트용으로 적합합니다.
- small (244M): VRAM 2GB 정도에서 동작하며, 한국어 인식이 실용적인 수준에 도달합니다. GPU가 없는 노트북에서도 reasonable한 속도로 작동합니다.
- medium (769M): VRAM 5GB 정도가 필요합니다. 한국어 인식 정확도가 눈에 띄게 좋아지며, 대부분의 일상 용도에 추천하는 모델입니다.
- large-v3 (1550M): 가장 정확한 모델입니다. VRAM 10GB 이상이 필요하지만, 전문 용어가 많은 회의나 발음이 불명확한 음성에서도 높은 정확도를 보여줍니다.
일반적으로 NVIDIA GPU가 장착된 데스크톱이라면 medium 이상을, GPU가 없는 노트북이라면 small 모델을 추천합니다. 최근에는 faster-whisper라는 최적화 버전이 나와서 같은 모델이라도 4~8배 빠른 속도로 변환이 가능해졌습니다.
설치부터 첫 변환까지 – 10분 안에 끝내는 환경 세팅
Python과 Whisper 설치하기
Whisper를 사용하려면 Python 환경이 필요합니다. Python이 처음이라도 괜찮습니다. 아래 순서대로 따라하면 10분 안에 첫 번째 음성 변환을 경험할 수 있습니다.
1단계: Python 설치 확인
터미널(윈도우는 명령 프롬프트 또는 PowerShell)을 열고 아래 명령어를 입력합니다.
python --version
Python 3.9 이상이 설치되어 있다면 다음 단계로 넘어갑니다. 설치되어 있지 않다면 python.org에서 최신 버전을 다운로드하여 설치합니다. 설치 시 “Add Python to PATH” 옵션을 반드시 체크해주세요.
2단계: faster-whisper 설치
원본 Whisper 대신 속도가 훨씬 빠른 faster-whisper를 설치합니다. 정확도는 동일하면서 변환 속도가 4~8배 빠릅니다.
pip install faster-whisper
NVIDIA GPU를 사용하는 경우, CUDA가 설치되어 있으면 자동으로 GPU 가속이 적용됩니다. GPU가 없어도 CPU로 충분히 동작하니 걱정하지 않아도 됩니다.
3단계: 첫 번째 음성 변환 실행
아래 Python 스크립트를 transcribe.py라는 이름으로 저장합니다.
from faster_whisper import WhisperModel
model = WhisperModel("medium", device="auto", compute_type="auto")
segments, info = model.transcribe("회의녹음.mp3", language="ko")
for segment in segments:
print(f"[{segment.start:.1f}s → {segment.end:.1f}s] {segment.text}")
“회의녹음.mp3” 부분을 자신의 음성 파일 이름으로 바꾸고, 터미널에서 python transcribe.py를 실행하면 됩니다. 첫 실행 시 모델 다운로드에 몇 분이 걸리지만, 이후에는 바로 변환이 시작됩니다.
지원하는 오디오 형식과 전처리 팁
Whisper는 mp3, wav, m4a, flac, ogg 등 대부분의 오디오 형식을 지원합니다. 스마트폰 녹음 앱의 기본 형식도 대부분 호환됩니다. 다만 변환 정확도를 높이려면 몇 가지 팁이 있습니다.
- 샘플레이트 16kHz 이상: 대부분의 녹음 앱은 기본적으로 이 조건을 충족하므로 별도 설정이 필요 없습니다.
- 배경 소음 제거: 카페나 식당에서 녹음한 파일은 소음 제거를 먼저 해주면 정확도가 크게 올라갑니다. 무료 오디오 편집 도구인 Audacity의 노이즈 리덕션 기능을 활용하면 됩니다.
- 스테레오보다 모노: 다채널 녹음은 모노로 변환한 뒤 처리하는 것이 더 안정적입니다.

실전 활용 시나리오 – 이런 상황에서 이렇게 쓰세요
시나리오 1: 팀 회의록 자동 생성
가장 많이 사용되는 시나리오입니다. Zoom이나 Teams 회의를 녹음한 뒤, Whisper로 텍스트 변환하고 AI로 요약하는 전체 워크플로우를 구성할 수 있습니다.
먼저, 회의 녹음 파일을 텍스트로 변환합니다. 앞서 설치한 faster-whisper를 사용하되, 화자 분리(Speaker Diarization) 기능을 추가하면 누가 어떤 말을 했는지까지 구분할 수 있습니다.
pip install pyannote.audio
pyannote.audio는 화자 분리를 위한 라이브러리입니다. Hugging Face 토큰이 필요하지만 무료로 사용 가능합니다. 화자 분리를 적용하면 결과물이 이렇게 달라집니다.
화자 분리 없이: “프로젝트 일정을 좀 당겨야 할 것 같습니다 그렇게 하면 리소스가 부족할 수 있는데요 QA 기간을 줄이는 건 위험하지 않을까요”
화자 분리 적용: “[화자1] 프로젝트 일정을 좀 당겨야 할 것 같습니다. [화자2] 그렇게 하면 리소스가 부족할 수 있는데요. [화자3] QA 기간을 줄이는 건 위험하지 않을까요?”
이렇게 변환된 텍스트를 Claude나 ChatGPT에 넣고 “아래 회의 내용을 핵심 결정사항, 액션 아이템, 논의 내용으로 구분해서 정리해줘”라고 요청하면, 깔끔한 회의록이 완성됩니다.
시나리오 2: 강의·세미나 노트 자동 생성
온라인 강의를 들을 때 필기하느라 정작 내용에 집중하지 못한 경험이 있을 겁니다. 강의를 녹음해두고 Whisper로 변환하면, 강의에만 온전히 집중할 수 있습니다.
강의 음성 변환 시에는 타임스탬프를 활용하는 것이 핵심입니다. 나중에 특정 부분을 다시 듣고 싶을 때 해당 시간으로 바로 이동할 수 있기 때문입니다.
변환된 강의 텍스트는 AI에게 “아래 강의 내용을 주제별로 분류하고, 핵심 개념을 불릿 포인트로 정리해줘”라고 요청하면 체계적인 학습 노트가 만들어집니다. 시험 준비할 때 특히 유용합니다.
시나리오 3: 유튜브 콘텐츠 제작 보조
유튜브 영상을 제작하는 분이라면, 촬영한 영상의 음성을 Whisper로 추출하여 자막 파일(SRT)을 자동 생성할 수 있습니다. faster-whisper는 SRT 형식 출력을 기본 지원합니다.
segments, info = model.transcribe("video.mp4", language="ko")
SRT 파일로 변환하는 코드 몇 줄만 추가하면, 수작업으로 몇 시간 걸리던 자막 작업이 몇 분 만에 끝납니다. 생성된 자막은 유튜브 스튜디오에 바로 업로드할 수 있고, 자막이 있는 영상은 검색 노출에도 유리합니다.
시나리오 4: 인터뷰·상담 기록 정리
프리랜서, 연구자, 상담사 등 인터뷰나 상담을 자주 하는 분들에게도 유용합니다. 대화 내용을 녹음(상대방 동의 필수)한 뒤 텍스트로 변환하면, 중요한 내용을 놓치지 않고 기록할 수 있습니다. 특히 연구 인터뷰의 경우 전사(transcription) 작업에 드는 시간과 비용을 획기적으로 줄일 수 있습니다.
Whisper AI 한국어 인식 정확도를 극대화하는 고급 설정
프롬프트 힌트로 전문 용어 인식률 높이기
Whisper에는 initial_prompt라는 강력한 옵션이 있습니다. 변환 전에 음성에 등장할 가능성이 높은 단어나 문맥을 미리 알려주는 기능입니다. 이를 활용하면 전문 용어 인식률이 크게 향상됩니다.
segments, info = model.transcribe(
"tech_meeting.mp3",
language="ko",
initial_prompt="쿠버네티스, 도커, CI/CD 파이프라인, 마이크로서비스, API 게이트웨이"
)
IT 회의라면 기술 용어를, 의료 상담이라면 의학 용어를, 법률 미팅이라면 법률 용어를 미리 넣어주면 됩니다. 이 한 줄이 인식 정확도를 체감할 수 있을 만큼 끌어올려줍니다.
VAD(Voice Activity Detection) 필터 활용
긴 녹음 파일에는 말이 없는 구간(침묵, 배경음악, 잡음)이 많습니다. faster-whisper의 VAD 필터를 활성화하면 실제 음성이 있는 구간만 처리하여 속도와 정확도를 동시에 개선할 수 있습니다.
segments, info = model.transcribe(
"long_recording.mp3",
language="ko",
vad_filter=True,
vad_parameters=dict(min_silence_duration_ms=500)
)
min_silence_duration_ms를 500으로 설정하면 0.5초 이상의 침묵 구간을 건너뜁니다. 2시간짜리 세미나 녹음도 실제 음성 부분만 빠르게 처리되니 효율적입니다.
beam_size와 temperature 튜닝
좀 더 세밀한 제어가 필요하다면 beam_size와 temperature 설정을 조절할 수 있습니다.
- beam_size: 기본값은 5입니다. 값을 높이면(예: 10) 더 많은 후보를 탐색하여 정확도가 올라가지만 속도가 느려집니다. 중요한 녹음은 beam_size를 높이고, 빠른 확인이 필요할 때는 1~3으로 낮추세요.
- temperature: 0에 가까울수록 보수적으로 인식하고, 높을수록 창의적(?)으로 인식합니다. 정확한 전사가 목적이라면 0으로 설정하는 것이 좋습니다.
이 옵션들은 처리 속도와 정확도 사이의 트레이드오프이므로, 자신의 용도에 맞게 조절하면 됩니다.
AI 요약까지 연결하는 자동화 파이프라인 만들기
전체 자동화 흐름 설계
Whisper로 음성을 텍스트로 바꾸는 것은 첫 단계에 불과합니다. 여기에 AI 요약을 연결하면 진정한 자동화가 완성됩니다. 전체 흐름은 이렇습니다.
음성 파일 입력 → Whisper 텍스트 변환 → AI 요약·정리 → 결과물 저장·공유
이 파이프라인을 하나의 Python 스크립트로 구성하면, 음성 파일을 지정 폴더에 넣기만 해도 자동으로 회의록이 생성되는 시스템을 만들 수 있습니다.
Python 스크립트로 파이프라인 구성하기
아래는 음성 파일을 텍스트로 변환하고, AI API를 통해 요약까지 완료하는 전체 스크립트의 핵심 구조입니다.
먼저 필요한 패키지를 설치합니다.
pip install faster-whisper anthropic
그리고 다음과 같은 구조의 스크립트를 작성합니다.
from faster_whisper import WhisperModel
import anthropic
# 1단계: 음성을 텍스트로 변환
model = WhisperModel("medium", device="auto")
segments, info = model.transcribe("meeting.mp3", language="ko", vad_filter=True)
full_text = "\n".join([s.text for s in segments])
# 2단계: AI로 요약
client = anthropic.Anthropic()
message = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=2000,
messages=[{"role": "user", "content": f"다음 회의 내용을 핵심 결정사항, 액션 아이템, 주요 논의 사항으로 구분해서 정리해줘:\n\n{full_text}"}]
)
# 3단계: 결과 저장
with open("회의록_요약.md", "w", encoding="utf-8") as f:
f.write(message.content[0].text)
이 스크립트를 실행하면 음성 파일 하나에서 깔끔하게 정리된 마크다운 회의록이 자동으로 생성됩니다.
폴더 감시로 완전 자동화하기
한 단계 더 나아가, 특정 폴더에 음성 파일이 들어오면 자동으로 변환이 시작되도록 만들 수 있습니다. Python의 watchdog 라이브러리를 사용하면 됩니다.
pip install watchdog
watchdog으로 폴더를 감시하다가 mp3, m4a, wav 파일이 새로 추가되면 자동으로 변환 파이프라인을 실행하는 구조입니다. 회의가 끝나고 녹음 파일을 해당 폴더에 저장하기만 하면, 몇 분 뒤 같은 폴더에 정리된 회의록 파일이 생성됩니다.
이 방식은 팀 공유 폴더(NAS, Google Drive, Dropbox)와 연동하면 더욱 강력해집니다. 팀원 누구든 녹음 파일을 올리면 자동으로 회의록이 생성되는 시스템을 구축할 수 있습니다.

보안과 프라이버시 – 왜 로컬 실행이 중요한가
클라우드 음성 인식 서비스의 프라이버시 이슈
시중에는 Clova Note, 네이버 클로바 등 편리한 클라우드 기반 음성 인식 서비스가 많습니다. 하지만 이런 서비스를 사용하면 음성 파일이 외부 서버로 전송됩니다. 사내 기밀 회의, 개인 상담, 법률 미팅 등 민감한 내용을 다루는 경우에는 보안상 부담이 될 수 있습니다.
Whisper를 로컬에서 실행하면 음성 데이터가 내 컴퓨터를 절대 벗어나지 않습니다. 인터넷 연결 없이도 작동하므로, 보안이 중요한 환경에서 안심하고 사용할 수 있습니다.
기업 환경에서의 활용과 주의사항
기업에서 Whisper를 도입할 때 몇 가지 고려해야 할 사항이 있습니다.
- 녹음 동의: 회의 참석자에게 녹음 사실을 반드시 알리고 동의를 받아야 합니다. 이는 법적 요구사항이기도 합니다.
- 데이터 보관 정책: 변환된 텍스트와 원본 음성 파일의 보관 기간과 삭제 정책을 미리 수립하세요.
- 접근 권한 관리: 변환된 회의록에 대한 접근 권한을 적절히 설정하여, 참석자 외 다른 사람이 열람하지 못하도록 관리해야 합니다.
이런 정책만 잘 갖추면, Whisper는 기업 환경에서도 강력한 생산성 도구로 활용될 수 있습니다.
마무리 – 음성 인식 자동화가 바꾸는 일상
Whisper AI를 활용한 음성-텍스트 변환은 단순한 기술 도구 이상의 가치가 있습니다. 회의에서 필기 대신 대화에 집중할 수 있고, 강의에서 놓친 내용을 다시 확인할 수 있으며, 중요한 인터뷰 내용을 빠짐없이 기록할 수 있습니다.
특히 이 모든 것이 무료로, 내 컴퓨터에서, 개인정보 걱정 없이 가능하다는 점이 Whisper의 가장 큰 매력입니다. 오늘 소개한 방법대로 설치하고 첫 번째 음성 파일을 변환해보세요. 한 번 경험하면 다시는 수동으로 회의록을 작성하고 싶지 않을 겁니다.
다음 단계로는 이 파이프라인을 Obsidian이나 Notion과 연결하여 자동으로 지식 관리 시스템에 통합하는 것을 추천합니다. 음성으로 말하고, AI가 정리하고, 자동으로 저장되는 완전한 지식 관리 워크플로우를 구축할 수 있습니다.
참고 자료
- OpenAI Whisper GitHub 공식 저장소 — Whisper 모델의 소스 코드, 설치 방법, 지원 언어 목록 등을 확인할 수 있는 공식 레포지토리
- Wikipedia: Whisper (speech recognition system) — Whisper 모델의 개발 배경, 아키텍처, 성능 벤치마크를 정리한 위키백과 문서

