
[Cloudflare 완전 정복: 입문부터 2026 AI 에이전트까지] 12/16화: Workers AI 엣지 LLM 호출 실전 가이드: Cloudflare AI 완전 정복
이 글은 「Cloudflare 완전 정복」 시리즈 12회입니다. 지난 11회에서 Wrangler CLI로 시크릿 관리와 로컬 개발 환경을 완성했으니, 이번에는 그 토대 위에 Workers AI를 올려 GPU 한 장 없이 엣지에서 LLM을 호출하는 실전 방법을 처음부터 끝까지 다룹니다.
Workers AI란 — GPU 없이 AI 모델을 내 코드에 연결하는 법
Workers AI는 Cloudflare의 글로벌 엣지 네트워크에 배치된 GPU 인프라를 통해 서버리스로 AI 모델을 실행하는 플랫폼입니다. 개발자가 GPU 인스턴스를 프로비저닝하거나 모델 가중치를 다운로드할 필요 없이, Worker 코드 안에서 env.AI.run() 한 줄로 텍스트 생성·임베딩·이미지 생성·음성 합성까지 처리합니다.
기존 AI API 서비스(OpenAI, Anthropic 등)와의 결정적 차이는 실행 위치입니다. 일반적인 클라우드 AI 서비스는 us-east-1 같은 특정 리전의 데이터센터에서 추론을 실행하지만, Workers AI는 사용자와 가장 가까운 엣지 노드의 GPU에서 실행합니다. 한국 사용자의 요청은 서울이나 도쿄 PoP에서 처리되므로, 미국 동부까지 왕복하는 200ms 이상의 네트워크 레이턴시가 사라집니다.
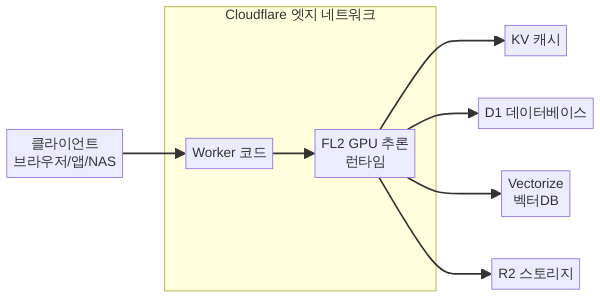
더 중요한 점은 Workers 생태계와의 네이티브 통합입니다. 9회에서 배운 Workers, 10회의 KV·D1·Durable Objects, 11회의 Wrangler 시크릿 관리 — 이 모든 것이 Workers AI와 하나의 코드베이스에서 자연스럽게 결합됩니다. LLM 응답을 D1에 캐싱하고, 임베딩 벡터를 Vectorize에 저장하고, 생성된 이미지를 R2에 업로드하는 파이프라인을 단일 Worker 프로젝트로 구현할 수 있습니다.
왜 엣지 추론인가 — 레이턴시·비용·프라이버시의 삼각형
레이턴시: 물리적 거리의 한계를 돌파
AI 추론의 체감 속도는 두 가지로 결정됩니다. 모델이 토큰을 생성하는 연산 시간과, 요청·응답이 네트워크를 오가는 전송 시간입니다. 대형 모델의 연산 시간은 어디서 실행하든 비슷하지만, 전송 시간은 물리적 거리에 비례합니다.
서울에서 미국 동부 리전까지 왕복 레이턴시는 약 180~250ms입니다. 스트리밍 응답에서 첫 토큰이 도착하기까지(TTFT, Time To First Token) 이 네트워크 레이턴시가 고스란히 더해집니다. Workers AI는 서울 PoP에서 직접 추론을 실행하므로, TTFT를 수십 ms 수준으로 줄입니다.
비용: 쓴 만큼만, 콜드 스타트 없이
GPU 인스턴스를 직접 운영하면 사용하지 않는 시간에도 비용이 발생합니다. AWS의 p4d.24xlarge(A100 8장)는 시간당 $32.77 — 하루 $786, 한 달이면 약 3,100만 원입니다. 트래픽이 간헐적인 개인 프로젝트나 MVP에는 치명적인 구조입니다.
Workers AI는 뉴런(neuron) 단위 과금을 사용합니다. 뉴런은 입력 토큰과 출력 토큰의 가중 합산으로 계산되며, 모델별 변환 계수가 다릅니다. 무료 플랜에서 하루 1만 뉴런을 제공하고, 초과분은 1,000뉴런당 $0.011입니다. 하루 100건의 짧은 LLM 호출 정도는 무료 한도 안에서 충분히 소화됩니다.
프라이버시: 데이터가 리전을 떠나지 않는다
Workers AI의 추론 요청은 엣지에서 처리되고, Cloudflare는 입력과 출력을 로깅하거나 모델 학습에 사용하지 않습니다. GDPR이나 개인정보보호법 준수가 필요한 서비스에서 사용자 데이터를 제3자 AI API에 전송하는 것이 부담스러울 때, 엣지 추론은 현실적인 대안이 됩니다.
FL2 아키텍처 — Cloudflare AI 인프라의 심장
Workers AI의 성능을 이해하려면 그 아래에 있는 FL2(Firecracker-Like Layer 2) 아키텍처를 알아야 합니다. FL2는 Cloudflare가 자체 개발한 Rust 기반 추론 런타임으로, 기존 Python 중심의 AI 서빙 스택(vLLM, TensorRT-LLM 등)과 근본적으로 다른 접근을 취합니다.
FL2의 핵심 특징은 다음과 같습니다:
- Rust 네이티브: Python GIL의 제약 없이 멀티코어 CPU와 GPU를 최대한 활용합니다. 메모리 안전성은 Rust 타입 시스템이 컴파일 타임에 보장합니다.
- 적응형 배칭: 여러 사용자의 요청을 GPU 배치로 묶어 처리합니다. 배치 크기는 현재 부하에 따라 동적으로 조절되어, 낮은 레이턴시와 높은 처리량을 동시에 달성합니다.
- KV 캐시 공유: 같은 시스템 프롬프트를 사용하는 요청들이 KV 캐시를 공유하여, 반복적인 프리필(prefill) 연산을 건너뜁니다.
- 글로벌 분산: 전 세계 주요 PoP에 GPU가 배치되어 있으며, 지능형 라우팅이 가장 여유 있는 노드로 요청을 전달합니다.
Cloudflare의 공식 벤치마크에 따르면 FL2는 전 세계 주요 네트워크 대비 약 60% 높은 추론 성능을 보여줍니다. 특히 소형·중형 모델(7B~70B 파라미터)에서 TTFT와 초당 토큰 생성 속도(TPS) 모두 경쟁 우위가 두드러집니다.
2026년 모델 카탈로그 — 텍스트부터 음성까지
Workers AI의 가장 큰 장점 중 하나는 지속적으로 확장되는 모델 카탈로그입니다. 2026년 6월 기준, 주요 카테고리별 모델을 정리합니다.

텍스트 생성 (Text Generation)
텍스트 생성은 Workers AI에서 가장 활발하게 사용되는 카테고리입니다. 챗봇, 요약, 번역, 코드 생성 등 다양한 용도에 활용됩니다.
- @cf/moonshotai/kimi-k2.6: Moonshot AI의 최신 MoE(Mixture of Experts) 모델. 1조 파라미터 규모지만 활성 파라미터는 32B로 효율적입니다. 다국어 성능이 뛰어나 한국어 작업에 적합합니다.
- @cf/nvidia/nemotron-3-8b: NVIDIA Nemotron 3 시리즈의 8B 모델. 코드 생성과 구조화된 출력(JSON 모드)에 강점을 보입니다.
- @cf/ibm/granite-3.2-8b-instruct: IBM Granite 시리즈. 엔터프라이즈 문서 처리와 RAG 파이프라인에 최적화되어 있으며, Apache 2.0 라이선스로 상업적 사용이 자유롭습니다.
- @cf/meta/llama-4-scout-17b: Meta의 Llama 4 Scout. 17B 파라미터로 속도와 품질의 균형이 좋아 범용 챗봇에 추천합니다.
- @cf/meta/llama-3.3-70b-instruct-fp8-fast: Llama 3.3 70B의 FP8 양자화 버전. 대형 모델의 품질을 유지하면서 추론 속도를 높인 실용적인 선택지입니다.
- @cf/mistral/mistral-small-3.2-24b-instruct: Mistral의 24B 모델. 유럽어와 코드에 특화되어 있으며, 함수 호출(function calling) 지원이 우수합니다.
- @cf/qwen/qwen2.5-coder-32b-instruct: 알리바바 Qwen 시리즈의 코딩 특화 모델. 코드 리뷰, 리팩토링, 테스트 생성에 탁월합니다.
텍스트 임베딩 (Text Embeddings)
- @cf/baai/bge-large-en-v1.5: BAAI의 영어 임베딩 모델. 1024차원 벡터를 생성하며, MTEB 벤치마크에서 상위권 성능을 유지합니다.
- @cf/baai/bge-m3: 다국어 임베딩 모델. 한국어를 포함한 100개 이상 언어를 지원하며, Dense·Sparse·ColBERT 세 가지 임베딩을 동시에 생성합니다.
- @cf/jina/jina-embeddings-v3: Jina AI의 최신 임베딩. 8192 토큰 컨텍스트 윈도를 지원하여 긴 문서 임베딩에 유리합니다.
이미지 생성 (Text-to-Image)
- @cf/stabilityai/stable-diffusion-xl-base-1.0: Stable Diffusion XL. 1024×1024 고해상도 이미지를 생성합니다.
- @cf/black-forest-labs/flux-1-schnell: FLUX.1 Schnell. 초고속 이미지 생성으로 실시간 프리뷰 용도에 적합합니다.
- @cf/bytedance/stable-diffusion-xl-lightning: SDXL Lightning. 4스텝만으로 고품질 이미지를 생성하는 증류(distilled) 모델입니다.
음성 처리 (Speech)
- @cf/openai/whisper-large-v3-turbo: OpenAI Whisper의 Turbo 변형. 음성을 텍스트로 변환(STT)하며, 한국어 인식 정확도가 높습니다.
- @cf/deepgram/aura-2-thalia-en: Deepgram Aura 2 시리즈의 TTS(Text-to-Speech) 모델. 자연스러운 영어 음성을 실시간으로 합성합니다.
기타
- 이미지 분류: @cf/microsoft/resnet-50 — 1000 카테고리 이미지 분류.
- 객체 탐지: @cf/facebook/detr-resnet-50 — 바운딩 박스 + 라벨 탐지.
- 번역: @cf/meta/m2m100-1.2b — 100개 언어 간 직접 번역.
- 텍스트 분류: @cf/huggingface/distilbert-sst-2-int8 — 감성 분석.
- 요약: @cf/facebook/bart-large-cnn — 뉴스·문서 자동 요약.
모델 카탈로그는 https://developers.cloudflare.com/workers-ai/models/에서 최신 목록을 확인할 수 있으며, Cloudflare changelog를 통해 신규 모델이 지속 추가됩니다. 위 목록은 2026년 6월 기준이므로 실제 작업 시 공식 문서를 함께 참고하세요.
5분 만에 첫 Workers AI Worker 배포하기
이론은 충분합니다. 이제 실제로 Workers AI를 사용하는 Worker를 만들어 배포해 봅시다. 11회에서 익힌 Wrangler CLI를 활용합니다.
프로젝트 생성
# Mac Studio 또는 Windows 터미널에서
npx wrangler@latest init my-ai-worker
cd my-ai-worker프로젝트 유형을 물으면 “Hello World” Worker를 선택합니다. TypeScript를 권장합니다.
wrangler.toml에 AI 바인딩 추가
wrangler.toml 파일을 열어 AI 바인딩을 선언합니다. 이 한 줄이 Workers AI 전체 모델 카탈로그로의 관문입니다.
name = "my-ai-worker"
main = "src/index.ts"
compatibility_date = "2026-06-01"
[ai]
binding = "AI"[ai] 섹션의 binding = "AI"는 Worker 코드에서 env.AI로 접근할 수 있는 바인딩 객체를 생성합니다. KV나 D1 바인딩과 같은 패턴이죠. 10회에서 배운 바인딩 개념이 그대로 적용됩니다.
Worker 코드 작성
src/index.ts를 다음과 같이 작성합니다:
export interface Env {
AI: Ai;
}
export default {
async fetch(request: Request, env: Env): Promise<Response> {
if (request.method !== "POST") {
return new Response("POST /로 질문을 보내세요", { status: 405 });
}
const body = await request.json() as { prompt: string };
const response = await env.AI.run(
"@cf/meta/llama-4-scout-17b",
{
messages: [
{ role: "system", content: "당신은 친절한 한국어 AI 어시스턴트입니다." },
{ role: "user", content: body.prompt }
],
max_tokens: 512,
temperature: 0.7
}
);
return Response.json(response);
}
} satisfies ExportedHandler<Env>;핵심은 env.AI.run() 호출입니다. 첫 번째 인자는 모델 ID, 두 번째는 모델별 입력 파라미터입니다. 텍스트 생성 모델은 OpenAI와 유사한 messages 배열을 받습니다.
로컬 테스트
# 로컬 개발 서버 시작
npx wrangler dev
# 다른 터미널에서 테스트
curl -X POST http://localhost:8787 \
-H "Content-Type: application/json" \
-d '{"prompt": "Cloudflare Workers AI를 세 줄로 설명해줘"}'wrangler dev는 Workers AI 바인딩을 실제 Cloudflare 네트워크로 프록시합니다. 로컬에서도 실제 GPU 추론 결과를 받아볼 수 있습니다. 단, 로컬 개발 중에도 무료 한도가 소비되니 참고하세요.
배포
npx wrangler deploy배포가 완료되면 https://my-ai-worker.<your-subdomain>.workers.dev로 전 세계 어디서든 접근할 수 있는 AI API가 생깁니다. GPU 서버 설정도, Docker 컨테이너도, 로드 밸런서도 필요 없었습니다.
텍스트 생성 심화 — 시스템 프롬프트, 파라미터, 함수 호출
시스템 프롬프트 설계
Workers AI의 텍스트 생성 모델은 OpenAI 호환 메시지 포맷을 사용합니다. 시스템 프롬프트로 모델의 행동을 제어합니다:
const response = await env.AI.run("@cf/meta/llama-4-scout-17b", {
messages: [
{
role: "system",
content: `당신은 한국 요리 전문가입니다.
규칙:
- 모든 레시피는 4인분 기준으로 작성
- 재료는 한국 마트에서 구할 수 있는 것만 사용
- 조리 시간을 반드시 명시
- 답변은 300자 이내로 간결하게`
},
{ role: "user", content: "간단한 된장찌개 레시피 알려줘" }
],
max_tokens: 1024,
temperature: 0.5,
top_p: 0.9
});핵심 파라미터 가이드
- max_tokens: 생성할 최대 토큰 수. 한국어는 글자당 약 1.5~2 토큰을 소비하므로, 500자 응답이 필요하면 1024 정도로 설정합니다.
- temperature: 0.0(결정적)~2.0(창의적). 정보 추출은 0.1~0.3, 창작은 0.7~1.0이 적절합니다.
- top_p: 누적 확률 상위 p%의 토큰만 후보로 사용. temperature와 함께 조절하되, 둘 다 극단값으로 설정하지 않습니다.
- top_k: 확률 상위 k개 토큰만 후보로 사용. 작은 값(10~40)은 안정적이고, 큰 값(100+)은 다양한 출력을 생성합니다.
- repetition_penalty: 1.0 이상으로 설정하면 같은 토큰의 반복 생성을 억제합니다. 1.1~1.2가 일반적입니다.
- seed: 동일한 시드로 동일한 입력을 보내면 재현 가능한 출력을 생성합니다(온도 0과 함께 사용 시).
JSON 모드 — 구조화된 출력 강제
LLM의 출력을 프로그래밍적으로 처리하려면 구조화된 포맷이 필수입니다. Workers AI는 response_format 파라미터로 JSON 출력을 강제할 수 있습니다:
const response = await env.AI.run("@cf/meta/llama-4-scout-17b", {
messages: [
{
role: "system",
content: `사용자가 설명하는 음식의 영양 정보를 JSON으로 반환하세요.
형식: {"name": "음식명", "calories": 숫자, "protein_g": 숫자, "carbs_g": 숫자, "fat_g": 숫자}`
},
{ role: "user", content: "김치볶음밥 한 그릇" }
],
response_format: { type: "json_object" },
max_tokens: 256,
temperature: 0.1
});
// response.response를 JSON.parse()로 안전하게 파싱
const nutrition = JSON.parse(response.response);
console.log(`칼로리: ${nutrition.calories}kcal`);함수 호출(Tool Use) 패턴
일부 모델(@cf/mistral/mistral-small-3.2-24b-instruct 등)은 함수 호출을 지원합니다. 외부 API 연동이나 데이터베이스 조회를 LLM이 판단하여 호출하게 만들 수 있습니다:
const response = await env.AI.run("@cf/mistral/mistral-small-3.2-24b-instruct", {
messages: [
{ role: "system", content: "사용자 요청에 적절한 도구를 호출하세요." },
{ role: "user", content: "서울 날씨 알려줘" }
],
tools: [
{
type: "function",
function: {
name: "get_weather",
description: "특정 도시의 현재 날씨를 조회합니다",
parameters: {
type: "object",
properties: {
city: { type: "string", description: "도시 이름" }
},
required: ["city"]
}
}
}
]
});
// response.tool_calls에 모델이 호출하려는 함수 정보가 담김
if (response.tool_calls) {
const call = response.tool_calls[0];
// call.function.name === "get_weather"
// call.function.arguments === '{"city": "서울"}'
// → 실제 날씨 API 호출 후 결과를 다시 모델에 전달
}이 패턴은 13회에서 다룰 AI 에이전트의 핵심 메커니즘으로 직결됩니다. Workers AI의 함수 호출이 곧 에이전트의 “도구 사용” 능력이 되는 셈입니다.
스트리밍 응답 — SSE로 실시간 토큰 전달
사용자 경험에서 가장 중요한 것은 첫 응답까지의 시간입니다. 500 토큰짜리 응답을 한 번에 기다리면 수 초가 걸리지만, 스트리밍으로 토큰 단위 전달하면 첫 글자가 수십 ms 만에 화면에 나타납니다.
Workers AI는 stream: true 옵션으로 Server-Sent Events(SSE) 스트리밍을 지원합니다:
export default {
async fetch(request: Request, env: Env): Promise<Response> {
const body = await request.json() as { prompt: string };
const stream = await env.AI.run(
"@cf/meta/llama-4-scout-17b",
{
messages: [
{ role: "system", content: "한국어로 답변하세요." },
{ role: "user", content: body.prompt }
],
max_tokens: 1024,
stream: true // ← 이 한 줄이 전부
}
);
// stream은 ReadableStream — 그대로 Response에 전달
return new Response(stream, {
headers: {
"Content-Type": "text/event-stream",
"Cache-Control": "no-cache",
"Connection": "keep-alive"
}
});
}
};클라이언트 측에서는 EventSource API 또는 fetch의 스트림 리더로 수신합니다:
// 브라우저 JavaScript
const response = await fetch("https://my-ai-worker.example.workers.dev", {
method: "POST",
headers: { "Content-Type": "application/json" },
body: JSON.stringify({ prompt: "한국의 사계절을 설명해줘" })
});
const reader = response.body.getReader();
const decoder = new TextDecoder();
while (true) {
const { done, value } = await reader.read();
if (done) break;
const chunk = decoder.decode(value);
// SSE 포맷: "data: {\"response\":\"토\"}\n\n"
const lines = chunk.split("\n").filter(l => l.startsWith("data: "));
for (const line of lines) {
const text = line.slice(6); // "data: " 제거
if (text === "[DONE]") break;
const parsed = JSON.parse(text);
// parsed.response에 토큰 단위 텍스트
document.getElementById("output").textContent += parsed.response;
}
}SSE 스트리밍은 5회에서 설정한 Cloudflare Tunnel을 통해서도 정상 동작합니다. Tunnel은 HTTP/2 기반이므로 장시간 스트리밍 연결을 안정적으로 유지합니다.
임베딩과 Vectorize — 나만의 시맨틱 검색 구축
임베딩이란
텍스트 임베딩은 문장을 고차원 벡터(숫자 배열)로 변환하는 것입니다. 의미가 유사한 문장은 벡터 공간에서 가까이 위치하므로, 키워드 매칭이 아닌 의미 기반 검색이 가능해집니다. “서울 날씨”와 “수도 기온”은 키워드가 완전히 다르지만, 임베딩 벡터는 매우 유사합니다.
Workers AI + Vectorize 조합
Cloudflare Vectorize는 Workers AI의 임베딩 모델과 네이티브로 통합되는 벡터 데이터베이스입니다. 문서를 임베딩하여 저장하고, 쿼리 텍스트로 유사 문서를 검색하는 파이프라인을 구축할 수 있습니다.
먼저 Vectorize 인덱스를 생성합니다:
# Vectorize 인덱스 생성 (bge-m3의 1024차원에 맞춤)
npx wrangler vectorize create my-knowledge-base \
--dimensions 1024 \
--metric cosinewrangler.toml에 Vectorize 바인딩을 추가합니다:
[ai]
binding = "AI"
[[vectorize]]
binding = "VECTORIZE"
index_name = "my-knowledge-base"문서 인덱싱 Worker
interface Env {
AI: Ai;
VECTORIZE: VectorizeIndex;
}
// 문서를 임베딩하여 Vectorize에 저장
async function indexDocument(env: Env, id: string, text: string, metadata: object) {
// 1. 텍스트를 벡터로 변환
const embedding = await env.AI.run("@cf/baai/bge-m3", {
text: [text]
});
// 2. Vectorize에 저장
await env.VECTORIZE.upsert([
{
id,
values: embedding.data[0],
metadata: { ...metadata, text: text.slice(0, 500) } // 메타데이터에 원문 일부 저장
}
]);
}
// 쿼리로 유사 문서 검색
async function searchDocuments(env: Env, query: string, topK: number = 5) {
// 1. 쿼리를 벡터로 변환
const queryEmbedding = await env.AI.run("@cf/baai/bge-m3", {
text: [query]
});
// 2. 유사 벡터 검색
const results = await env.VECTORIZE.query(queryEmbedding.data[0], {
topK,
returnMetadata: "all"
});
return results.matches;
}시맨틱 검색 → LLM 답변(RAG) 전체 파이프라인
검색된 문서를 컨텍스트로 LLM에 전달하면, 할루시네이션을 줄인 사실 기반 답변이 가능해집니다. 이것이 RAG(Retrieval-Augmented Generation) 패턴입니다:
export default {
async fetch(request: Request, env: Env): Promise<Response> {
const { query } = await request.json() as { query: string };
// 1단계: 유사 문서 검색
const matches = await searchDocuments(env, query, 3);
const context = matches
.map(m => m.metadata?.text ?? "")
.join("\n---\n");
// 2단계: 컨텍스트와 함께 LLM 질의
const answer = await env.AI.run("@cf/meta/llama-4-scout-17b", {
messages: [
{
role: "system",
content: `아래 참고 문서를 바탕으로 질문에 답변하세요.
참고 문서에 없는 내용은 "해당 정보를 찾을 수 없습니다"라고 답하세요.
[참고 문서]
${context}`
},
{ role: "user", content: query }
],
max_tokens: 1024,
temperature: 0.3
});
return Response.json({
answer: answer.response,
sources: matches.map(m => ({
id: m.id,
score: m.score,
preview: (m.metadata?.text ?? "").slice(0, 100)
}))
});
}
};
이 RAG 파이프라인의 모든 구성 요소 — 임베딩 생성, 벡터 검색, 텍스트 생성 — 가 Cloudflare 엣지 안에서 완결됩니다. 외부 API 호출이 없으므로 레이턴시가 극도로 낮고, 데이터가 Cloudflare 네트워크 밖으로 나가지 않아 프라이버시도 보장됩니다.
이미지 생성 — 엣지에서 실시간 비주얼 만들기
Workers AI는 텍스트뿐 아니라 이미지 생성도 지원합니다. 블로그 썸네일, 소셜 미디어 카드, 프로토타입 목업을 API 한 번 호출로 만들 수 있습니다.
export default {
async fetch(request: Request, env: Env): Promise<Response> {
const { prompt } = await request.json() as { prompt: string };
const response = await env.AI.run(
"@cf/black-forest-labs/flux-1-schnell",
{
prompt,
num_steps: 4 // Schnell은 4스텝이면 충분
}
);
// response는 ReadableStream (PNG 바이너리)
return new Response(response, {
headers: { "Content-Type": "image/png" }
});
}
};생성 이미지를 R2에 자동 저장
8회에서 다룬 R2와 조합하면, 생성된 이미지를 자동으로 오브젝트 스토리지에 저장하고 퍼블릭 URL로 서빙할 수 있습니다:
interface Env {
AI: Ai;
IMAGES: R2Bucket; // R2 바인딩
}
export default {
async fetch(request: Request, env: Env): Promise<Response> {
const { prompt } = await request.json() as { prompt: string };
// 1. 이미지 생성
const imageData = await env.AI.run(
"@cf/black-forest-labs/flux-1-schnell",
{ prompt, num_steps: 4 }
);
// 2. R2에 저장
const key = `generated/${Date.now()}.png`;
await env.IMAGES.put(key, imageData, {
httpMetadata: { contentType: "image/png" },
customMetadata: { prompt }
});
// 3. 퍼블릭 URL 반환
return Response.json({
url: `https://images.example.com/${key}`,
prompt
});
}
};음성 처리 — STT와 TTS를 엣지에서
음성 → 텍스트 (Whisper STT)
Whisper 모델로 오디오 파일을 텍스트로 변환합니다. 팟캐스트 트랜스크립션, 음성 메모 변환, 실시간 자막 생성 등에 활용됩니다:
export default {
async fetch(request: Request, env: Env): Promise<Response> {
// 오디오 파일을 바이너리로 수신
const audioBuffer = await request.arrayBuffer();
const result = await env.AI.run("@cf/openai/whisper-large-v3-turbo", {
audio: [...new Uint8Array(audioBuffer)]
});
return Response.json({
text: result.text, // 전체 텍스트
segments: result.vtt, // VTT 형식 타임스탬프
word_count: result.word_count
});
}
};텍스트 → 음성 (Deepgram TTS)
Deepgram Aura 2 모델로 텍스트를 자연스러운 음성으로 변환합니다:
export default {
async fetch(request: Request, env: Env): Promise<Response> {
const { text } = await request.json() as { text: string };
const audioStream = await env.AI.run(
"@cf/deepgram/aura-2-thalia-en",
{ text }
);
return new Response(audioStream, {
headers: {
"Content-Type": "audio/wav",
"Content-Disposition": "inline"
}
});
}
};음성 → LLM → 음성 파이프라인
STT와 TTS를 LLM과 조합하면 음성 기반 AI 어시스턴트가 됩니다:
export default {
async fetch(request: Request, env: Env): Promise<Response> {
// 1. 음성 → 텍스트
const audioBuffer = await request.arrayBuffer();
const stt = await env.AI.run("@cf/openai/whisper-large-v3-turbo", {
audio: [...new Uint8Array(audioBuffer)]
});
// 2. 텍스트 → LLM 응답
const llm = await env.AI.run("@cf/meta/llama-4-scout-17b", {
messages: [
{ role: "system", content: "간결하게 답변하세요." },
{ role: "user", content: stt.text }
],
max_tokens: 256
});
// 3. LLM 응답 → 음성
const tts = await env.AI.run("@cf/deepgram/aura-2-thalia-en", {
text: llm.response
});
return new Response(tts, {
headers: { "Content-Type": "audio/wav" }
});
}
};세 번의 AI 호출이 모두 Cloudflare 엣지 안에서 일어나므로, 외부 API 왕복 없이 음성 질의 → 음성 응답 전체 사이클이 완성됩니다.
AI Gateway — 모니터링·캐싱·레이트 리밋의 컨트롤 타워
Workers AI를 프로덕션에 배포하면 모니터링과 비용 제어가 중요해집니다. AI Gateway는 Workers AI 호출에 대한 관측성(observability) 레이어를 제공합니다.
AI Gateway 설정
Cloudflare 대시보드에서 AI → AI Gateway로 이동하여 게이트웨이를 생성합니다. 이름을 지정하면 고유 엔드포인트가 할당됩니다.
wrangler.toml에서 AI 바인딩에 게이트웨이를 연결합니다:
[ai]
binding = "AI"
# AI Gateway 연결
[[ai.gateway]]
id = "my-ai-gateway" # 대시보드에서 생성한 게이트웨이 IDAI Gateway가 제공하는 기능
- 실시간 로깅: 모든 AI 호출의 입력·출력·토큰 수·레이턴시를 대시보드에서 확인합니다. 프롬프트 디버깅에 필수적입니다.
- 비용 추적: 모델별·시간대별 뉴런 소비량을 시각화합니다. 예상치 못한 비용 급증을 사전에 감지할 수 있습니다.
- 응답 캐싱: 동일한 입력에 대한 응답을 캐싱하여 GPU 연산을 절약합니다. FAQ 봇이나 정적 쿼리가 많은 서비스에서 효과적입니다.
- 레이트 리밋: 사용자당/IP당 분당 요청 수를 제한하여 남용을 방지합니다.
- 폴백(Fallback): Workers AI 외에 OpenAI, Anthropic 등 외부 AI 제공자를 폴백으로 설정할 수 있습니다. 특정 모델에 장애가 발생하면 자동으로 대체 모델로 라우팅합니다.
// AI Gateway를 통한 호출 — 코드 변경 없이 게이트웨이 기능 적용
const response = await env.AI.run("@cf/meta/llama-4-scout-17b", {
messages: [
{ role: "user", content: "안녕하세요" }
]
});
// 바인딩에 gateway가 설정되어 있으면 자동으로 게이트웨이를 경유D1과 함께 쓰는 실전 패턴 — 대화 이력 저장
챗봇을 만들 때 대화 이력을 유지하려면 상태 저장소가 필요합니다. 10회에서 배운 D1 데이터베이스와 조합하면 완전한 대화형 AI 서비스가 됩니다:
interface Env {
AI: Ai;
DB: D1Database;
}
// D1 스키마 (wrangler d1 execute로 실행)
// CREATE TABLE conversations (
// id TEXT PRIMARY KEY,
// session_id TEXT NOT NULL,
// role TEXT NOT NULL, -- 'user' | 'assistant'
// content TEXT NOT NULL,
// created_at INTEGER DEFAULT (unixepoch())
// );
// CREATE INDEX idx_session ON conversations(session_id, created_at);
export default {
async fetch(request: Request, env: Env): Promise<Response> {
const { session_id, message } = await request.json() as {
session_id: string;
message: string;
};
// 1. 이전 대화 이력 조회 (최근 20건)
const history = await env.DB.prepare(
"SELECT role, content FROM conversations WHERE session_id = ? ORDER BY created_at DESC LIMIT 20"
).bind(session_id).all();
const messages = [
{ role: "system" as const, content: "친절한 한국어 어시스턴트입니다. 이전 대화 맥락을 참고하여 답변하세요." },
...history.results.reverse().map(row => ({
role: row.role as "user" | "assistant",
content: row.content as string
})),
{ role: "user" as const, content: message }
];
// 2. LLM 호출
const response = await env.AI.run("@cf/meta/llama-4-scout-17b", {
messages,
max_tokens: 1024
});
// 3. 사용자 메시지 + AI 응답을 D1에 저장
const batch = [
env.DB.prepare(
"INSERT INTO conversations (id, session_id, role, content) VALUES (?, ?, 'user', ?)"
).bind(crypto.randomUUID(), session_id, message),
env.DB.prepare(
"INSERT INTO conversations (id, session_id, role, content) VALUES (?, ?, 'assistant', ?)"
).bind(crypto.randomUUID(), session_id, response.response)
];
await env.DB.batch(batch);
return Response.json({ response: response.response });
}
};D1은 Workers와 같은 엣지에서 실행되므로, 대화 이력 조회에 추가 네트워크 홉이 발생하지 않습니다. 10회에서 소개한 D1의 batch() 메서드로 두 건의 INSERT를 하나의 트랜잭션으로 묶어 일관성을 보장합니다.
OpenAI 호환 프록시 — 기존 도구 재활용
Workers AI의 자체 API도 좋지만, 이미 OpenAI SDK를 쓰는 클라이언트가 많다면 호환 엔드포인트가 편리합니다. Workers AI는 /v1/chat/completions 호환 모드를 기본 제공합니다:
# OpenAI 호환 엔드포인트로 직접 호출
curl -X POST https://api.cloudflare.com/client/v4/accounts/{ACCOUNT_ID}/ai/v1/chat/completions \
-H "Authorization: Bearer {API_TOKEN}" \
-H "Content-Type: application/json" \
-d '{
"model": "@cf/meta/llama-4-scout-17b",
"messages": [
{"role": "user", "content": "안녕하세요"}
]
}'또는 Worker 안에서 프록시를 직접 구현하여 커스텀 로직(인증, 로깅, 모델 라우팅)을 추가할 수도 있습니다:
export default {
async fetch(request: Request, env: Env): Promise<Response> {
const url = new URL(request.url);
// OpenAI 호환 라우트
if (url.pathname === "/v1/chat/completions") {
const body = await request.json() as {
model?: string;
messages: Array<{ role: string; content: string }>;
stream?: boolean;
max_tokens?: number;
temperature?: number;
};
// 모델 매핑: OpenAI 모델명 → Workers AI 모델명
const modelMap: Record<string, string> = {
"gpt-4": "@cf/meta/llama-4-scout-17b",
"gpt-3.5-turbo": "@cf/meta/llama-3.3-70b-instruct-fp8-fast",
"default": "@cf/meta/llama-4-scout-17b"
};
const aiModel = modelMap[body.model ?? "default"] ?? modelMap["default"];
const response = await env.AI.run(aiModel, {
messages: body.messages,
max_tokens: body.max_tokens ?? 1024,
temperature: body.temperature ?? 0.7,
stream: body.stream ?? false
});
if (body.stream) {
return new Response(response as ReadableStream, {
headers: { "Content-Type": "text/event-stream" }
});
}
// OpenAI 응답 포맷으로 래핑
return Response.json({
id: `chatcmpl-${crypto.randomUUID().slice(0, 8)}`,
object: "chat.completion",
created: Math.floor(Date.now() / 1000),
model: aiModel,
choices: [{
index: 0,
message: { role: "assistant", content: response.response },
finish_reason: "stop"
}]
});
}
return new Response("Not Found", { status: 404 });
}
};이 프록시를 배포하면 기존 OpenAI SDK를 사용하는 어떤 클라이언트도 base_url만 바꿔서 Workers AI 모델을 호출할 수 있습니다. Python 예시:
# Python (openai SDK 사용)
from openai import OpenAI
client = OpenAI(
base_url="https://my-ai-worker.example.workers.dev/v1",
api_key="dummy" # Worker에서 별도 인증 처리
)
response = client.chat.completions.create(
model="gpt-4", # 실제로는 Llama 4 Scout로 라우팅
messages=[{"role": "user", "content": "Workers AI 설명해줘"}]
)
print(response.choices[0].message.content)홈랩 실전 — Synology NAS에서 Workers AI 자동화
홈랩 환경에서 Workers AI를 활용하는 실전 시나리오를 두 가지 소개합니다.
시나리오 1: NAS 파일 자동 분류
Synology NAS DS+925에 업로드되는 문서를 Workers AI가 자동 분류하여 폴더에 정리하는 흐름입니다:
# Synology NAS SSH 접속 후 — 크론잡으로 새 파일 감지 및 분류 요청
# 1. Workers AI 분류 API 호출 스크립트 (classify.sh)
#!/bin/bash
WORKER_URL="https://my-ai-worker.example.workers.dev/classify"
# /volume1/incoming 폴더의 새 파일 목록
find /volume1/incoming -maxdepth 1 -type f -mmin -60 -name "*.txt" | while read file; do
CONTENT=$(head -c 2000 "$file") # 처음 2000바이트만 전송
FILENAME=$(basename "$file")
CATEGORY=$(curl -s -X POST "$WORKER_URL" \
-H "Content-Type: application/json" \
-d "{\"filename\": \"$FILENAME\", \"content\": \"$CONTENT\"}" \
| jq -r '.category')
# 분류 결과에 따라 이동
mkdir -p "/volume1/sorted/$CATEGORY"
mv "$file" "/volume1/sorted/$CATEGORY/$FILENAME"
echo "$(date): $FILENAME → $CATEGORY"
done분류 Worker 코드:
export default {
async fetch(request: Request, env: Env): Promise<Response> {
const { filename, content } = await request.json() as {
filename: string;
content: string;
};
const response = await env.AI.run("@cf/meta/llama-4-scout-17b", {
messages: [{
role: "system",
content: `파일 이름과 내용을 보고 카테고리를 하나만 반환하세요.
카테고리: invoice, receipt, contract, report, personal, other
JSON 형식: {"category": "..."}`
}, {
role: "user",
content: `파일명: ${filename}\n내용:\n${content.slice(0, 1500)}`
}],
response_format: { type: "json_object" },
max_tokens: 64,
temperature: 0.1
});
const result = JSON.parse(response.response);
return Response.json(result);
}
};시나리오 2: Mac Studio에서 개발 중 AI 코드 리뷰
Mac Studio에서 Git 커밋 전에 Workers AI로 코드 리뷰를 자동 실행하는 pre-commit 훅입니다:
# Mac Studio — .git/hooks/pre-commit
#!/bin/bash
WORKER_URL="https://my-ai-worker.example.workers.dev/review"
DIFF=$(git diff --cached --diff-filter=ACMR)
if [ -z "$DIFF" ]; then exit 0; fi
# diff를 Workers AI에 전송하여 리뷰
REVIEW=$(curl -s -X POST "$WORKER_URL" \
-H "Content-Type: application/json" \
-d "{\"diff\": $(echo "$DIFF" | jq -Rs .)}" \
| jq -r '.review')
echo "=== AI Code Review ==="
echo "$REVIEW"
echo "======================"
# 심각한 이슈가 있으면 커밋 차단 (선택)
SEVERITY=$(curl -s -X POST "$WORKER_URL" \
-H "Content-Type: application/json" \
-d "{\"diff\": $(echo "$DIFF" | jq -Rs .)}" \
| jq -r '.severity')
if [ "$SEVERITY" = "critical" ]; then
echo "❌ Critical issue detected. Fix before committing."
exit 1
fi성능 최적화 팁
1. 모델 선택이 곧 최적화
모든 작업에 가장 큰 모델을 쓸 필요는 없습니다. 용도별 추천:
- 단순 분류·감성 분석: @cf/huggingface/distilbert-sst-2-int8 — 텍스트 생성 모델보다 10배 이상 빠릅니다.
- 짧은 QA·요약: Llama 4 Scout 17B — 속도와 품질의 균형.
- 복잡한 추론·코드 생성: Llama 3.3 70B FP8 — 더 느리지만 품질이 확실히 높습니다.
- 임베딩: bge-m3 (다국어) 또는 bge-large-en (영어 전용) — 다국어 서비스면 m3, 영어만이면 large-en이 약간 더 정확합니다.
2. 프롬프트 길이 최소화
입력 토큰이 줄면 프리필 시간과 비용이 모두 줄어듭니다. 시스템 프롬프트는 간결하게, 컨텍스트는 핵심만 추출하여 전달합니다. RAG에서 검색 결과를 3건 이상 넣을 때는 관련도 점수로 필터링하세요.
3. 응답 캐싱 전략
동일한 질문이 반복되는 서비스(FAQ 봇, 상품 설명 등)에서는 KV에 응답을 캐싱합니다:
interface Env {
AI: Ai;
CACHE: KVNamespace;
}
export default {
async fetch(request: Request, env: Env): Promise<Response> {
const { prompt } = await request.json() as { prompt: string };
// 캐시 키: 프롬프트의 해시
const cacheKey = `ai:${await digestMessage(prompt)}`;
const cached = await env.CACHE.get(cacheKey);
if (cached) {
return Response.json({ response: cached, cached: true });
}
const response = await env.AI.run("@cf/meta/llama-4-scout-17b", {
messages: [{ role: "user", content: prompt }],
max_tokens: 1024,
temperature: 0 // 캐싱 시 결정적 출력
});
// 1시간 TTL로 캐싱
await env.CACHE.put(cacheKey, response.response, { expirationTtl: 3600 });
return Response.json({ response: response.response, cached: false });
}
};
async function digestMessage(message: string): Promise<string> {
const data = new TextEncoder().encode(message);
const hash = await crypto.subtle.digest("SHA-256", data);
return [...new Uint8Array(hash)].map(b => b.toString(16).padStart(2, "0")).join("");
}4. 병렬 호출로 레이턴시 축소
독립적인 AI 작업은 Promise.all()로 병렬 실행합니다:
// 요약 + 감성 분석 + 키워드 추출을 병렬로
const [summary, sentiment, keywords] = await Promise.all([
env.AI.run("@cf/facebook/bart-large-cnn", { input_text: article }),
env.AI.run("@cf/huggingface/distilbert-sst-2-int8", { text: article }),
env.AI.run("@cf/meta/llama-4-scout-17b", {
messages: [{
role: "user",
content: `다음 글에서 핵심 키워드 5개를 추출하세요: ${article.slice(0, 1000)}`
}],
max_tokens: 100
})
]);5. max_tokens 적극 제한
필요한 출력 길이를 예측하여 max_tokens를 최소화하면 불필요한 토큰 생성을 방지합니다. 분류 작업에 max_tokens: 10, 한 줄 요약에 max_tokens: 100 등으로 제한하세요. 출력 토큰은 입력 토큰보다 비용 가중치가 높으므로 비용 절감 효과가 큽니다.
에러 처리와 레이트 리밋 대응
프로덕션 환경에서는 Workers AI 호출 실패에 대비해야 합니다. 일반적인 에러 시나리오와 대응 방법입니다:
async function callAIWithRetry(
env: Env,
model: string,
input: object,
maxRetries: number = 3
): Promise<unknown> {
for (let attempt = 0; attempt < maxRetries; attempt++) {
try {
return await env.AI.run(model, input);
} catch (error) {
const err = error as Error;
// 레이트 리밋 초과 — 지수 백오프
if (err.message.includes("rate limit")) {
const delay = Math.pow(2, attempt) * 1000;
await new Promise(resolve => setTimeout(resolve, delay));
continue;
}
// 모델 과부하 — 대체 모델로 폴백
if (err.message.includes("overloaded")) {
const fallbackModels: Record<string, string> = {
"@cf/meta/llama-4-scout-17b": "@cf/meta/llama-3.3-70b-instruct-fp8-fast",
"@cf/meta/llama-3.3-70b-instruct-fp8-fast": "@cf/mistral/mistral-small-3.2-24b-instruct"
};
const fallback = fallbackModels[model];
if (fallback && attempt === 0) {
model = fallback;
continue;
}
}
// 마지막 시도에서도 실패하면 에러 전파
if (attempt === maxRetries - 1) throw error;
}
}
throw new Error("AI call failed after all retries");
}전체 아키텍처 정리 — Workers AI 풀스택 구성
지금까지 다룬 구성 요소를 하나로 모으면, Workers AI를 중심으로 한 풀스택 AI 서비스의 전체 그림이 그려집니다:
┌─────────────┐
│ 클라이언트 │ (브라우저 / 모바일 / NAS 크론잡 / CLI)
└──────┬──────┘
│ HTTPS
▼
┌──────────────────────────────────────────────┐
│ Worker (엣지) │
│ ┌──────────┐ ┌──────────┐ ┌──────────────┐│
│ │ 라우팅/인증│ │ 비즈니스 │ │ AI 오케스트레│ │
│ │ │→ │ 로직 │→ │ 이션 ││
│ └──────────┘ └──────────┘ └──────┬───────┘│
│ │ │
│ ┌──────────────────────────────────┼────┐ │
│ │ Workers AI (GPU 추론) │ │ │
│ │ ┌─────────┐ ┌──────┐ ┌────────┐│ │ │
│ │ │텍스트 생성│ │임베딩 │ │이미지 ││ │ │
│ │ └─────────┘ └──────┘ └────────┘│ │ │
│ └──────────────────────────────────┘ │ │
│ │ │
│ ┌─────┐ ┌─────┐ ┌──────────┐ ┌────┐ │ │
│ │ D1 │ │ KV │ │ Vectorize│ │ R2 │ │ │
│ │(대화)│ │(캐시)│ │(벡터검색) │ │(미디│ │ │
│ └─────┘ └─────┘ └──────────┘ │어) │ │ │
│ └────┘ │ │
└──────────────────────────────────────────────┘9회의 Workers가 컴퓨팅 기반, 10회의 KV·D1·DO가 데이터 레이어, 11회의 Wrangler가 개발·배포 도구, 그리고 이번 12회의 Workers AI가 지능 레이어 — Phase 3의 네 회차가 하나의 풀스택으로 조립됩니다.
완전한 프로젝트 예시 — AI 블로그 요약 서비스
지금까지 배운 모든 요소를 결합한 실전 프로젝트입니다. URL을 입력하면 웹페이지를 크롤링하여 AI가 요약·번역·키워드 추출을 수행하고, 결과를 D1에 저장하며, 이전 요약과의 유사도를 Vectorize로 검색합니다.
wrangler.toml
name = "ai-blog-summarizer"
main = "src/index.ts"
compatibility_date = "2026-06-01"
[ai]
binding = "AI"
[[d1_databases]]
binding = "DB"
database_name = "summaries"
database_id = "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx"
[[vectorize]]
binding = "VECTORS"
index_name = "summary-embeddings"
[[kv_namespaces]]
binding = "CACHE"
id = "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"핵심 코드
interface Env {
AI: Ai;
DB: D1Database;
VECTORS: VectorizeIndex;
CACHE: KVNamespace;
}
interface SummaryResult {
title: string;
summary_ko: string;
summary_en: string;
keywords: string[];
similar_articles: Array<{ id: string; title: string; score: number }>;
}
export default {
async fetch(request: Request, env: Env): Promise<Response> {
if (request.method !== "POST") {
return new Response("POST { url: string }", { status: 405 });
}
const { url } = await request.json() as { url: string };
// 1. 캐시 확인
const cacheKey = `summary:${url}`;
const cached = await env.CACHE.get(cacheKey, "json");
if (cached) return Response.json(cached);
// 2. 웹페이지 텍스트 추출 (간소화)
const pageResponse = await fetch(url);
const html = await pageResponse.text();
const textContent = html
.replace(/<script[\s\S]*?<\/script>/gi, "")
.replace(/<style[\s\S]*?<\/style>/gi, "")
.replace(/<[^>]+>/g, " ")
.replace(/\s+/g, " ")
.trim()
.slice(0, 4000);
// 3. 병렬 AI 처리: 요약(한/영) + 키워드 추출 + 임베딩
const [summaryKo, summaryEn, keywordsResult, embedding] = await Promise.all([
// 한국어 요약
env.AI.run("@cf/meta/llama-4-scout-17b", {
messages: [
{ role: "system", content: "주어진 글을 3~5문장의 한국어로 요약하세요." },
{ role: "user", content: textContent }
],
max_tokens: 512,
temperature: 0.3
}),
// 영어 요약
env.AI.run("@cf/meta/llama-4-scout-17b", {
messages: [
{ role: "system", content: "Summarize the given text in 3-5 sentences in English." },
{ role: "user", content: textContent }
],
max_tokens: 512,
temperature: 0.3
}),
// 키워드 추출
env.AI.run("@cf/meta/llama-4-scout-17b", {
messages: [
{ role: "system", content: '핵심 키워드 5개를 JSON 배열로 반환. 예: ["키워드1","키워드2"]' },
{ role: "user", content: textContent }
],
response_format: { type: "json_object" },
max_tokens: 100,
temperature: 0.1
}),
// 임베딩 생성
env.AI.run("@cf/baai/bge-m3", { text: [textContent.slice(0, 2000)] })
]);
// 4. 유사 글 검색
const similar = await env.VECTORS.query(embedding.data[0], {
topK: 3,
returnMetadata: "all"
});
// 5. 결과 조립
let keywords: string[] = [];
try {
const parsed = JSON.parse(keywordsResult.response);
keywords = Array.isArray(parsed) ? parsed : parsed.keywords ?? [];
} catch {
keywords = [];
}
const result: SummaryResult = {
title: url,
summary_ko: summaryKo.response,
summary_en: summaryEn.response,
keywords,
similar_articles: similar.matches.map(m => ({
id: m.id,
title: (m.metadata?.title as string) ?? m.id,
score: m.score
}))
};
// 6. D1에 저장 + Vectorize에 인덱싱
const docId = crypto.randomUUID();
await Promise.all([
env.DB.prepare(
"INSERT INTO summaries (id, url, summary_ko, summary_en, keywords) VALUES (?, ?, ?, ?, ?)"
).bind(docId, url, result.summary_ko, result.summary_en, JSON.stringify(keywords)).run(),
env.VECTORS.upsert([{
id: docId,
values: embedding.data[0],
metadata: { title: url, summary: result.summary_ko.slice(0, 200) }
}])
]);
// 7. 캐시에 저장 (6시간 TTL)
await env.CACHE.put(cacheKey, JSON.stringify(result), { expirationTtl: 21600 });
return Response.json(result);
}
};이 프로젝트 하나에 Workers AI(텍스트 생성 + 임베딩), D1(영속 저장), Vectorize(유사도 검색), KV(캐시), fetch API(외부 크롤링)가 모두 동원됩니다. 외부 인프라 없이 npx wrangler deploy 한 번으로 전 세계에 배포되는 AI 서비스입니다.
Synology NAS에서 정기 실행 — 크론 자동화
위의 블로그 요약 서비스를 Synology NAS DS+925의 작업 스케줄러로 자동화하는 설정입니다:
# Synology NAS — SSH 접속 후 스크립트 생성
cat > /volume1/scripts/daily-summarize.sh << 'EOF'
#!/bin/bash
# 매일 RSS 피드에서 새 글을 가져와 Workers AI로 요약
WORKER_URL="https://ai-blog-summarizer.example.workers.dev"
RSS_URLS=(
"https://blog.cloudflare.com/rss/"
"https://tech.kakao.com/feed/"
"https://engineering.linecorp.com/ko/feed/"
)
for rss in "${RSS_URLS[@]}"; do
# RSS에서 최근 글 URL 추출 (간소화)
URLS=$(curl -s "$rss" | grep -oP '(?<=)https?://[^<]+' | head -5)
for url in $URLS; do
echo "Summarizing: $url"
curl -s -X POST "$WORKER_URL" \
-H "Content-Type: application/json" \
-d "{\"url\": \"$url\"}" | jq '.summary_ko' >> /volume1/logs/summaries-$(date +%Y%m%d).log
sleep 2 # 레이트 리밋 방지
done
done
EOF
chmod +x /volume1/scripts/daily-summarize.shSynology DSM의 제어판 → 작업 스케줄러에서 "사용자 지정 스크립트" 작업을 만들고, 매일 오전 7시에 /volume1/scripts/daily-summarize.sh를 실행하도록 설정합니다.
월 비용 명세표
Workers AI의 과금 구조를 정리합니다. 2026년 6월 기준입니다.
| 항목 | 무료 (Free) | Workers Paid ($5/월~) | 비고 |
|---|---|---|---|
| 뉴런 | 일 10,000 뉴런 | 무제한 (초과분 과금) | 초과: $0.011 / 1,000 뉴런 |
| Workers 요청 | 일 100,000 요청 | 월 1,000만 요청 포함 | 초과: $0.30 / 100만 요청 |
| D1 읽기 | 일 500만 행 | 월 250억 행 포함 | 초과: $0.001 / 100만 행 |
| D1 쓰기 | 일 100,000 행 | 월 5,000만 행 포함 | 초과: $1.00 / 100만 행 |
| KV 읽기 | 일 100,000 요청 | 월 1,000만 요청 포함 | 초과: $0.50 / 100만 요청 |
| KV 쓰기 | 일 1,000 요청 | 월 100만 요청 포함 | 초과: $5.00 / 100만 요청 |
| Vectorize 쿼리 | 월 30,000 쿼리 | 월 5,000만 쿼리 포함 | 초과: $0.040 / 1,000 쿼리 |
| Vectorize 저장 | 5,000 벡터 | 1,000만 벡터 포함 | 초과: $0.040 / 100만 벡터/월 |
| R2 저장 | 10GB | 10GB 포함 | 초과: $0.015 / GB/월 |
| R2 송신 | $0 (무제한) | $0 (무제한) | 8회 참조 |
| AI Gateway | 무료 | 무료 | 로깅·캐싱·레이트리밋 포함 |
실사용 시나리오별 월 예상 비용
| 시나리오 | 일 사용량 | 월 예상 비용 |
|---|---|---|
| 개인 챗봇 (일 50회 질의) | ~5,000 뉴런 | $0 (무료 한도 내) |
| 블로그 요약 봇 (일 100건) | ~8,000 뉴런 | $0 (무료 한도 내) |
| 소규모 SaaS (일 1,000회 질의) | ~50,000 뉴런 | ~$5 + Workers Paid $5 = 약 $10 |
| RAG 서비스 (일 500건, 임베딩 포함) | ~30,000 뉴런 | ~$3 + Workers Paid $5 = 약 $8 |
| 이미지 생성 서비스 (일 200건) | ~40,000 뉴런 | ~$4 + Workers Paid $5 = 약 $9 |
개인 프로젝트나 프로토타입은 무료 한도 안에서 충분히 운영 가능합니다. 소규모 상업 서비스도 월 $10 이하로 AI 기능을 제공할 수 있어, GPU 인스턴스 직접 운영 대비 수백 분의 1 수준의 비용입니다.

Workers AI의 한계와 대안
Workers AI가 만능은 아닙니다. 다음 한계를 인지하고 적절한 대안을 고려하세요:
- 모델 크기 제한: Workers AI는 엣지 GPU에서 실행 가능한 크기의 모델만 제공합니다. 최전선 대형 모델(파라미터 400B+)이 필요하면 OpenAI, Anthropic API를 AI Gateway를 통해 사용하는 것이 현실적입니다.
- 파인튜닝 미지원: 현재 Workers AI는 사전 학습된 모델만 제공하며, 커스텀 파인튜닝은 지원하지 않습니다. 도메인 특화 성능이 필요하면 프롬프트 엔지니어링과 RAG로 보완하거나, 외부에서 파인튜닝한 모델을 AI Gateway로 라우팅합니다.
- 긴 컨텍스트 윈도: 대부분의 Workers AI 모델은 컨텍스트 윈도가 4K~32K 토큰입니다. 100K+ 토큰이 필요한 작업에는 부적합합니다.
- 멀티모달 제약: 이미지 입력(비전) 모델은 카탈로그가 제한적입니다. 복잡한 멀티모달 작업에는 외부 API가 더 적합할 수 있습니다.
이러한 한계에도 불구하고, 빠른 응답이 필요한 실시간 서비스, 비용 민감한 개인·소규모 프로젝트, 데이터 프라이버시가 중요한 서비스에서 Workers AI는 여전히 최적의 선택지입니다.
마무리 — 다음 회 예고
이번 12회에서 Workers AI를 통해 GPU 없이 엣지에서 LLM, 임베딩, 이미지 생성, 음성 처리까지 가능하다는 것을 확인했습니다. 특히 D1·KV·Vectorize·R2와의 네이티브 통합 덕분에 외부 인프라 의존 없이 AI 서비스를 만들 수 있다는 점이 Workers AI의 진정한 강점입니다.
Phase 3(개발자 플랫폼)은 이번 회로 마무리됩니다. 9회 Workers → 10회 스토리지 → 11회 Wrangler → 12회 Workers AI로 이어진 네 회차를 통해, Cloudflare 위에서 풀스택 AI 애플리케이션을 구축하는 기반을 모두 다졌습니다.
다음 13회부터는 시리즈의 시그니처 구간인 Phase 4: 2026 AI 에이전트 시대에 진입합니다. 13회에서는 2026 Agents Week에서 발표된 Cloudflare Sandboxes, Dynamic Workers, Workflows v2 — AI 에이전트가 자율적으로 코드를 실행하고 파일을 조작하는 영속 환경을 해부합니다. Workers AI가 에이전트의 "두뇌"라면, Sandboxes는 에이전트의 "손과 발"입니다.
◀ 이전 11화 (다음 차수는 아직 게시되지 않았습니다)
참고 자료
- Cloudflare Workers AI 공식 문서 — 모델 카탈로그, 바인딩 설정, API 레퍼런스를 포함한 공식 개발자 가이드
- Edge computing — Wikipedia — 엣지 컴퓨팅의 개념과 아키텍처를 설명하는 위키백과 문서


[…] Cloudflare 완전 정복: 입문부터 2026 AI 에이전트까지 (총 16화 중 13화)◀ 이전 12화 (다음 차수는 아직 게시되지 않았습니다) Tags:Agents Week 2026AI […]