
이 글은 「Cloudflare 완전 정복」 시리즈의 11회입니다. 지난 9화에서 Workers의 첫 배포를, 10화에서 KV·D1·Durable Objects의 선택 기준을 다뤘습니다. 이번에는 그 모든 것을 실전 수준으로 끌어올리는 도구인 Wrangler CLI를 깊이 파헤쳐, 시크릿 관리부터 환경 분리, 로컬 개발까지 한 번에 익혀 보겠습니다.
대시보드 클릭은 잊어라 — Wrangler CLI가 필요한 이유
Cloudflare 대시보드에서 Workers를 만들고 코드를 붙여넣는 방식은 학습용으로는 훌륭하지만, 실제 서비스를 운영하기엔 한계가 명확합니다. API 키를 코드에 하드코딩할 수 없고, staging과 production을 분리해야 하며, 팀원이 늘어나면 배포 이력을 추적해야 합니다.
Wrangler는 Cloudflare의 공식 CLI 도구로, Workers·Pages·R2·D1·KV·Durable Objects 등 개발자 플랫폼의 거의 모든 리소스를 터미널에서 관리합니다. 2026년 현재 Wrangler 4.x 시대에 접어들며, 단순 배포 도구를 넘어 로컬 개발 런타임까지 내장한 올인원 개발 환경으로 진화했습니다.
이번 화에서 다루는 핵심 세 가지입니다:
- 시크릿(Secrets) — DB 비밀번호, API 키를 안전하게 주입하는 방법
- 환경(Environments) — 하나의 코드베이스로 staging·production을 분리 운영
- 로컬 개발(Local Dev) — 배포 없이 내 PC에서 Workers를 실행하고 디버깅하는 방법
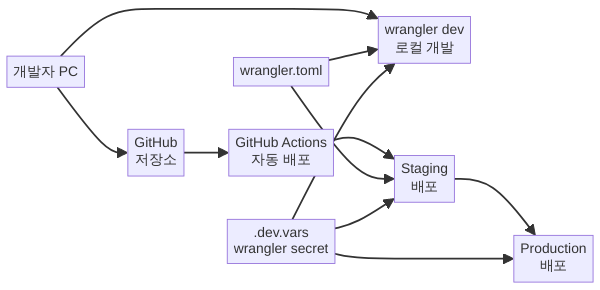
Wrangler 설치와 인증 — 5분 셋업
Node.js 환경 준비
Wrangler는 npm 패키지로 배포됩니다. Node.js 18 이상이 필요하며, 2026년 기준 Node.js 22 LTS를 권장합니다. Mac Studio 홈랩이라면 Homebrew로, Synology NAS라면 Docker 컨테이너 안에서 실행하는 방식이 가장 깔끔합니다.
# Mac Studio — Homebrew로 Node.js 설치 (이미 있다면 생략)
brew install node@22
# Wrangler 전역 설치
npm install -g wrangler
# 버전 확인
wrangler --version
# ⚡ wrangler 4.x.x# Synology NAS — Docker 컨테이너에서 Wrangler 사용
docker run --rm -it -v $(pwd):/app -w /app node:22-slim bash -c \
"npm install -g wrangler && wrangler --version"프로젝트 단위로 설치하는 것도 좋은 습관입니다. 팀원마다 Wrangler 버전이 달라 생기는 문제를 예방합니다:
# 프로젝트 로컬 설치 (권장)
npm install --save-dev wrangler
# npx로 실행
npx wrangler --versionCloudflare 계정 인증
Wrangler를 Cloudflare 계정에 연결하는 방법은 두 가지입니다:
# 방법 1: OAuth 브라우저 인증 (개인 개발용, 권장)
wrangler login
# 브라우저가 열리고 Cloudflare 로그인 → 권한 승인
# 성공하면 ~/.wrangler/config/default.toml에 토큰 저장# 방법 2: API 토큰 환경변수 (CI/CD·헤드리스 환경용)
export CLOUDFLARE_API_TOKEN="your-api-token-here"
export CLOUDFLARE_ACCOUNT_ID="your-account-id"
# 토큰은 Cloudflare 대시보드 → My Profile → API Tokens에서 생성
# "Edit Cloudflare Workers" 템플릿 사용 권장인증 상태를 확인하려면:
wrangler whoami
# 출력 예시:
# ⛅️ wrangler 4.x.x
# Getting User settings...
# 👋 You are logged in with an OAuth Token, associated with the email '[email protected]'!
# ┌─────────────────────┬──────────────────────────────────┐
# │ Account Name │ Account ID │
# ├─────────────────────┼──────────────────────────────────┤
# │ My Account │ abcdef1234567890abcdef1234567890 │
# └─────────────────────┴──────────────────────────────────┘프로젝트 생성과 wrangler.toml 완전 해부
새 프로젝트 스캐폴딩
Wrangler는 init 명령으로 프로젝트 뼈대를 자동 생성합니다. 2026년 현재 create cloudflare (C3) CLI를 통한 생성이 공식 권장 경로이지만, Wrangler 단독으로도 충분합니다:
# 방법 1: C3로 생성 (템플릿 선택 가능)
npm create cloudflare@latest my-worker
# 방법 2: Wrangler로 직접 초기화
mkdir my-worker && cd my-worker
npm init -y
npm install --save-dev wrangler
npx wrangler init생성된 프로젝트 구조:
my-worker/
├── src/
│ └── index.ts # Worker 메인 코드
├── wrangler.toml # ⭐ Wrangler 설정 파일 — 핵심
├── package.json
└── tsconfig.jsonwrangler.toml — 모든 설정의 중심
wrangler.toml은 Worker의 이름, 실행 환경, 바인딩, 환경별 오버라이드를 한 곳에 정의하는 단일 설정 파일입니다. 9화에서 간단히 다뤘지만, 이번에는 실전 프로젝트에서 만나는 모든 필드를 살펴봅니다.
# wrangler.toml — 실전 프로젝트 예시
# ── 기본 설정 ──────────────────────────────────
name = "my-api" # Worker 이름 (URL: my-api.{subdomain}.workers.dev)
main = "src/index.ts" # 진입점 파일
compatibility_date = "2026-06-01" # Workers 런타임 호환성 날짜
compatibility_flags = ["nodejs_compat_v2"] # Node.js API 호환 플래그
# ── 빌드 설정 (선택) ──────────────────────────
[build]
command = "npm run build" # 커스텀 빌드 명령
watch_dir = "src" # 감시할 디렉토리
# ── 라우팅 ─────────────────────────────────────
routes = [
{ pattern = "api.example.com/*", zone_name = "example.com" }
]
# 또는 커스텀 도메인:
# [custom_domain]
# hostname = "api.example.com"
# ── KV 바인딩 ──────────────────────────────────
[[kv_namespaces]]
binding = "CACHE_KV" # 코드에서 env.CACHE_KV로 접근
id = "abcdef1234567890abcdef1234567890"
# ── D1 바인딩 ──────────────────────────────────
[[d1_databases]]
binding = "DB" # 코드에서 env.DB로 접근
database_name = "my-app-db"
database_id = "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx"
# ── R2 바인딩 ──────────────────────────────────
[[r2_buckets]]
binding = "ASSETS" # 코드에서 env.ASSETS로 접근
bucket_name = "my-assets"
# ── Durable Objects ────────────────────────────
[durable_objects]
bindings = [
{ name = "COUNTER", class_name = "Counter" }
]
[[migrations]]
tag = "v1"
new_classes = ["Counter"]
# ── 환경변수 (평문, 비밀 아닌 값) ─────────────
[vars]
APP_ENV = "production"
LOG_LEVEL = "info"
PUBLIC_API_URL = "https://api.example.com"
# ── 로그 ───────────────────────────────────────
[observability]
enabled = true # Workers Logs 활성화각 필드의 핵심 포인트를 짚겠습니다:
- compatibility_date: Workers 런타임의 동작 방식이 이 날짜 기준으로 고정됩니다. 새 프로젝트는 오늘 날짜로, 기존 프로젝트는 테스트 후 점진적으로 올립니다. 이 값을 바꾸면 런타임 동작이 달라질 수 있으므로 주의하세요.
- compatibility_flags:
nodejs_compat_v2를 켜면Buffer,crypto,stream등 Node.js 내장 모듈 상당수를 Workers에서 사용할 수 있습니다. - 바인딩(bindings): KV·D1·R2·Durable Objects 등 Cloudflare 리소스를 Worker 코드에 연결하는 선언. 10화에서 배운 스토리지들이 여기서 코드와 만납니다.
- [vars]: 평문 환경변수. 코드에서
env.APP_ENV으로 접근합니다. 절대 비밀 정보를 여기에 넣지 마세요. 시크릿은 별도 관리합니다.
시크릿 관리 — 민감 정보를 안전하게 주입하기
외부 API 키, 데이터베이스 비밀번호, JWT 서명 키 같은 민감 정보를 Workers에 전달해야 하는 경우는 매우 흔합니다. wrangler.toml의 [vars]에 넣으면 Git에 커밋되어 유출 위험이 생깁니다. Wrangler는 이를 위해 시크릿(Secrets) 기능을 제공합니다.
시크릿의 동작 원리
시크릿은 Cloudflare의 엣지 인프라에 암호화되어 저장되며, Worker가 실행될 때만 복호화되어 env 객체를 통해 접근 가능합니다. wrangler.toml에는 시크릿 값이 전혀 기록되지 않으므로, Git 저장소에 안전하게 커밋할 수 있습니다.
시크릿 등록과 관리
# 시크릿 추가 — 프롬프트로 값 입력 (터미널 히스토리에 남지 않음)
npx wrangler secret put DATABASE_PASSWORD
# 🌀 Enter a secret value: ********
# ✨ Success! Uploaded secret DATABASE_PASSWORD
# 파이프로 전달 (스크립트 자동화용)
echo "sk-abc123xyz" | npx wrangler secret put OPENAI_API_KEY
# 파일에서 읽기 (바이너리 시크릿, 인증서 등)
cat private-key.pem | npx wrangler secret put TLS_PRIVATE_KEY
# 현재 등록된 시크릿 목록 확인 (값은 표시되지 않음)
npx wrangler secret list
# [
# { "name": "DATABASE_PASSWORD", "type": "secret_text" },
# { "name": "OPENAI_API_KEY", "type": "secret_text" },
# { "name": "TLS_PRIVATE_KEY", "type": "secret_text" }
# ]
# 시크릿 삭제
npx wrangler secret delete OPENAI_API_KEY
# 🌀 Are you sure you want to permanently delete the secret OPENAI_API_KEY? (y/n) y
# ✨ Success! Deleted secret OPENAI_API_KEY코드에서 시크릿 사용
시크릿은 [vars]의 평문 변수와 동일한 방식으로 env 객체를 통해 접근합니다. 코드 입장에서는 둘의 차이가 없으므로 매우 직관적입니다:
// src/index.ts
export interface Env {
// wrangler.toml [vars]에 정의된 평문 변수
APP_ENV: string;
LOG_LEVEL: string;
// wrangler secret put으로 등록한 시크릿
DATABASE_PASSWORD: string;
OPENAI_API_KEY: string;
// 바인딩
DB: D1Database;
CACHE_KV: KVNamespace;
}
export default {
async fetch(request: Request, env: Env): Promise<Response> {
// 시크릿 사용 — env 객체에서 바로 접근
const dbResult = await env.DB.prepare(
"SELECT * FROM users WHERE id = ?"
).bind(1).first();
// 외부 API 호출에 시크릿 사용
const aiResponse = await fetch("https://api.openai.com/v1/chat/completions", {
method: "POST",
headers: {
"Authorization": `Bearer ${env.OPENAI_API_KEY}`,
"Content-Type": "application/json",
},
body: JSON.stringify({
model: "gpt-4o",
messages: [{ role: "user", content: "Hello" }],
}),
});
return new Response("OK");
},
};시크릿 관리 실전 팁
- .dev.vars 파일: 로컬 개발 시 시크릿을 대신할 값을
.dev.vars파일에 넣습니다. 이 파일은 반드시.gitignore에 추가하세요.
# .dev.vars — 로컬 개발용 시크릿 (Git에 커밋하지 않음!)
DATABASE_PASSWORD=local-dev-password-123
OPENAI_API_KEY=sk-test-key-for-development
JWT_SECRET=dev-jwt-secret-not-for-production# .gitignore에 추가
echo ".dev.vars" >> .gitignore- 시크릿 로테이션: 같은 이름으로
wrangler secret put을 다시 실행하면 덮어씁니다. 정기적인 키 로테이션이 간편합니다. - 환경별 시크릿:
--env플래그로 환경별로 다른 시크릿 값을 등록할 수 있습니다 (환경 분리 섹션에서 상세 설명). - 벌크 등록: Wrangler 4.x에서는
wrangler secret bulk명령으로 JSON 파일의 시크릿을 일괄 등록할 수 있습니다.
# secrets.json (일회용, 등록 후 삭제)
# {
# "DATABASE_PASSWORD": "super-secret-pw",
# "OPENAI_API_KEY": "sk-abc123",
# "WEBHOOK_SECRET": "whsec_xyz789"
# }
npx wrangler secret bulk secrets.json
# ✨ Successfully created secret for DATABASE_PASSWORD
# ✨ Successfully created secret for OPENAI_API_KEY
# ✨ Successfully created secret for WEBHOOK_SECRET
# 보안을 위해 즉시 삭제
rm secrets.json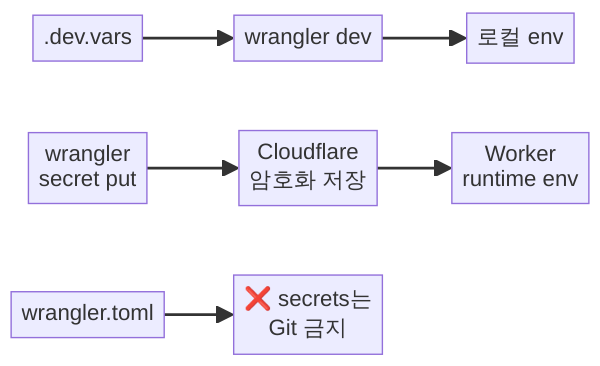
환경 분리 — 하나의 코드, staging과 production
실제 서비스를 운영하면 “개발 중인 코드를 프로덕션에 바로 배포”하는 것은 위험합니다. Wrangler는 wrangler.toml 안에서 환경(environments)을 정의해, 같은 코드베이스를 서로 다른 설정으로 배포할 수 있게 합니다.
환경 정의 — wrangler.toml 구조
# wrangler.toml — 환경 분리 예시
# ── 공통 설정 (모든 환경에 적용) ──────────────
name = "my-api"
main = "src/index.ts"
compatibility_date = "2026-06-01"
compatibility_flags = ["nodejs_compat_v2"]
[vars]
LOG_LEVEL = "warn" # 기본값 (환경별로 오버라이드 가능)
[observability]
enabled = true
# ── staging 환경 ───────────────────────────────
[env.staging]
name = "my-api-staging" # 별도의 Worker로 배포됨
vars = { LOG_LEVEL = "debug", APP_ENV = "staging" }
routes = [
{ pattern = "staging-api.example.com/*", zone_name = "example.com" }
]
[[env.staging.kv_namespaces]]
binding = "CACHE_KV"
id = "staging-kv-namespace-id-here" # staging용 KV
[[env.staging.d1_databases]]
binding = "DB"
database_name = "my-app-db-staging"
database_id = "staging-db-id-here" # staging용 D1
[[env.staging.r2_buckets]]
binding = "ASSETS"
bucket_name = "my-assets-staging" # staging용 R2
# ── production 환경 ────────────────────────────
[env.production]
name = "my-api-production"
vars = { LOG_LEVEL = "error", APP_ENV = "production" }
routes = [
{ pattern = "api.example.com/*", zone_name = "example.com" }
]
[[env.production.kv_namespaces]]
binding = "CACHE_KV"
id = "production-kv-namespace-id-here" # production용 KV
[[env.production.d1_databases]]
binding = "DB"
database_name = "my-app-db-production"
database_id = "production-db-id-here" # production용 D1
[[env.production.r2_buckets]]
binding = "ASSETS"
bucket_name = "my-assets-production" # production용 R2핵심 개념을 정리하면:
- 최상위 설정은 모든 환경의 기본값입니다.
[env.xxx]에서 같은 키를 정의하면 오버라이드됩니다. - 각 환경은 독립된 Worker로 배포됩니다.
name이 다르므로 URL도 다릅니다. - 바인딩(KV·D1·R2)도 환경별로 분리합니다. staging에서 production 데이터를 건드리는 사고를 원천 차단합니다.
환경별 배포 명령
# staging에 배포
npx wrangler deploy --env staging
# 🌀 Deploying to staging...
# ✨ Published my-api-staging
# https://my-api-staging.{subdomain}.workers.dev
# production에 배포
npx wrangler deploy --env production
# 🌀 Deploying to production...
# ✨ Published my-api-production
# https://my-api-production.{subdomain}.workers.dev
# 환경 미지정 시 최상위 설정으로 배포 (기본 환경)
npx wrangler deploy환경별 시크릿 등록
시크릿도 환경별로 분리됩니다. staging과 production에서 서로 다른 API 키를 사용하는 것은 필수입니다:
# staging 시크릿
npx wrangler secret put DATABASE_PASSWORD --env staging
# 🌀 Enter a secret value: [staging DB 비밀번호 입력]
# production 시크릿
npx wrangler secret put DATABASE_PASSWORD --env production
# 🌀 Enter a secret value: [production DB 비밀번호 입력]
# 환경별 시크릿 목록 확인
npx wrangler secret list --env staging
npx wrangler secret list --env production환경별 리소스 생성 — KV·D1 분리
10화에서 배운 KV와 D1도 환경별로 따로 만들어야 합니다:
# ── KV 네임스페이스 — 환경별 생성 ──
npx wrangler kv namespace create CACHE_KV
# ✨ Created namespace "my-api-CACHE_KV" (id: abc123...)
# → wrangler.toml 최상위 또는 [env.production]에 id 기입
npx wrangler kv namespace create CACHE_KV --env staging
# ✨ Created namespace "my-api-staging-CACHE_KV" (id: def456...)
# → [env.staging] 블록에 id 기입
# ── D1 데이터베이스 — 환경별 생성 ──
npx wrangler d1 create my-app-db-staging
# ✨ Created DB 'my-app-db-staging' (id: staging-db-id)
npx wrangler d1 create my-app-db-production
# ✨ Created DB 'my-app-db-production' (id: production-db-id)
# ── R2 버킷 — 환경별 생성 ──
npx wrangler r2 bucket create my-assets-staging
npx wrangler r2 bucket create my-assets-production실전 배포 전략 — 단계별 승격
추천하는 배포 흐름입니다:
# 1단계: 로컬 개발 (wrangler dev)
npx wrangler dev
# 2단계: staging 배포 + 검증
npx wrangler deploy --env staging
curl https://staging-api.example.com/healthz
# 3단계: production 배포
npx wrangler deploy --env production
# 4단계: 문제 발생 시 롤백
npx wrangler rollback --env production
# → 직전 배포 버전으로 즉시 롤백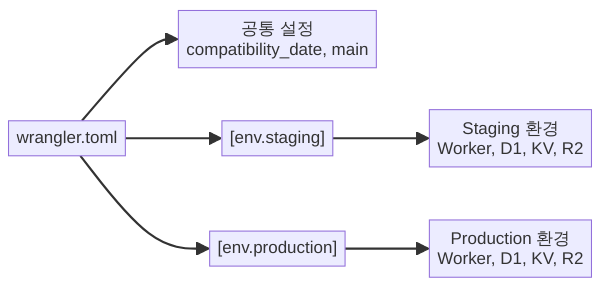
로컬 개발 — wrangler dev 완전 정복
wrangler dev는 Cloudflare Workers의 로컬 개발 서버입니다. 내부적으로 Miniflare 3(workerd 기반)를 사용해 Cloudflare 엣지 런타임을 로컬에서 거의 완벽하게 재현합니다. 코드를 저장할 때마다 자동 리로드되어 빠른 개발 루프를 만들어줍니다.
기본 실행
# 기본 로컬 개발 서버 시작
npx wrangler dev
# 출력 예시:
# ⎔ Starting local server...
# [wrangler:inf] Ready on http://localhost:8787
# [wrangler:inf] ─ GET / 200 OK (3ms)
# 다른 포트 사용
npx wrangler dev --port 3000
# 특정 환경의 설정으로 로컬 실행
npx wrangler dev --env staging
# 외부 접근 허용 (같은 네트워크 다른 기기에서 테스트)
npx wrangler dev --ip 0.0.0.0로컬 vs 리모트 모드
Wrangler dev는 두 가지 모드로 동작합니다:
# 로컬 모드 (기본, 권장) — 모든 것이 내 PC에서 실행
npx wrangler dev
# KV, D1, R2 등도 로컬 시뮬레이션 (.wrangler/state/에 데이터 저장)
# 리모트 모드 — Cloudflare 엣지에서 실행, 실제 바인딩 사용
npx wrangler dev --remote
# ⚠️ 실제 KV/D1/R2 데이터에 접근하므로 주의- 로컬 모드: KV·D1·R2가 로컬 파일시스템에 에뮬레이트됩니다. 인터넷 없이도 개발 가능하고, 실제 데이터를 건드리지 않아 안전합니다.
.wrangler/state/디렉토리에 상태가 저장됩니다. - 리모트 모드: 실제 Cloudflare 엣지에서 코드가 실행되고, 실제 바인딩에 연결됩니다. 최종 검증 단계에서만 사용을 권장합니다.
로컬 영속 데이터 — persist 옵션
# 기본적으로 로컬 KV/D1/R2 데이터는 .wrangler/state/에 영속
# wrangler dev를 재시작해도 데이터가 유지됨
# 데이터 저장 경로를 명시적으로 지정
npx wrangler dev --persist-to ./local-data
# 로컬 데이터 초기화 (깨끗한 상태에서 테스트)
rm -rf .wrangler/state/
npx wrangler dev로컬 D1에 시드 데이터 넣기
로컬 개발 시 D1 데이터베이스에 테스트용 데이터를 넣는 방법입니다:
# schema.sql 작성
cat > schema.sql <<'EOF'
CREATE TABLE IF NOT EXISTS users (
id INTEGER PRIMARY KEY AUTOINCREMENT,
name TEXT NOT NULL,
email TEXT UNIQUE NOT NULL,
created_at DATETIME DEFAULT CURRENT_TIMESTAMP
);
INSERT INTO users (name, email) VALUES
('홍길동', '[email protected]'),
('김철수', '[email protected]'),
('이영희', '[email protected]');
EOF
# 로컬 D1에 스키마 적용
npx wrangler d1 execute my-app-db-staging --local --file schema.sql
# ✨ Executed 2 commands successfully
# 로컬 D1 쿼리 테스트
npx wrangler d1 execute my-app-db-staging --local --command "SELECT * FROM users"
# ┌────┬────────┬──────────────────┬─────────────────────┐
# │ id │ name │ email │ created_at │
# ├────┼────────┼──────────────────┼─────────────────────┤
# │ 1 │ 홍길동 │ [email protected] │ 2026-06-12 09:00:00 │
# │ 2 │ 김철수 │ [email protected] │ 2026-06-12 09:00:00 │
# │ 3 │ 이영희 │ [email protected] │ 2026-06-12 09:00:00 │
# └────┴────────┴──────────────────┴─────────────────────┘.dev.vars — 로컬 시크릿 주입
앞서 시크릿 섹션에서 언급한 .dev.vars 파일의 상세한 활용법입니다:
# .dev.vars — wrangler dev 실행 시 자동으로 읽힘
DATABASE_PASSWORD=local-dev-password
OPENAI_API_KEY=sk-test-local-key
JWT_SECRET=dev-jwt-secret-32chars-minimum!!
WEBHOOK_SECRET=whsec-local-testing-onlywrangler dev를 실행하면 .dev.vars의 값이 env 객체에 자동 주입됩니다. wrangler.toml의 [vars]와 이름이 겹치면 .dev.vars가 우선합니다.
핫 리로드와 디버깅
# wrangler dev 실행 중 파일을 수정하면 자동 리로드
# src/index.ts를 저장 → 즉시 반영
# DevTools로 디버깅 (Chrome에서 열림)
npx wrangler dev --inspector-port 9229
# chrome://inspect로 접속해 디버깅 가능
# 로그 확인 — console.log는 터미널에 출력
# src/index.ts에서:
# console.log("Request received:", request.url);
# console.log("DB result:", JSON.stringify(result));로컬 개발 시 자주 쓰는 curl 테스트
# 기본 GET 요청
curl http://localhost:8787/
# POST with JSON body
curl -X POST http://localhost:8787/api/users \
-H "Content-Type: application/json" \
-d '{"name": "테스트", "email": "[email protected]"}'
# 인증 헤더 포함
curl http://localhost:8787/api/protected \
-H "Authorization: Bearer test-token-123"
# 응답 헤더까지 확인
curl -v http://localhost:8787/healthz
# SSE (Server-Sent Events) 스트리밍 테스트
curl -N http://localhost:8787/api/stream실전 프로젝트 — 완전한 API 서비스 구축
지금까지 배운 시크릿·환경·로컬 개발을 모두 결합한 실전 예제입니다. “할 일 목록(Todo)” API를 staging과 production으로 분리 운영하는 프로젝트를 만들어봅니다.
프로젝트 초기화
# 프로젝트 생성
mkdir todo-api && cd todo-api
npm init -y
npm install --save-dev wrangler typescript @cloudflare/workers-typeswrangler.toml 작성
# wrangler.toml
name = "todo-api"
main = "src/index.ts"
compatibility_date = "2026-06-01"
compatibility_flags = ["nodejs_compat_v2"]
[observability]
enabled = true
# ── staging ────────────────────────────────────
[env.staging]
name = "todo-api-staging"
vars = { APP_ENV = "staging", LOG_LEVEL = "debug" }
[[env.staging.d1_databases]]
binding = "DB"
database_name = "todo-db-staging"
database_id = "your-staging-db-id" # wrangler d1 create 후 ID 기입
# ── production ─────────────────────────────────
[env.production]
name = "todo-api-production"
vars = { APP_ENV = "production", LOG_LEVEL = "error" }
routes = [
{ pattern = "todo-api.example.com/*", zone_name = "example.com" }
]
[[env.production.d1_databases]]
binding = "DB"
database_name = "todo-db-production"
database_id = "your-production-db-id" # wrangler d1 create 후 ID 기입TypeScript 설정
// tsconfig.json
{
"compilerOptions": {
"target": "ES2022",
"module": "ES2022",
"moduleResolution": "bundler",
"lib": ["ES2022"],
"types": ["@cloudflare/workers-types"],
"strict": true,
"noEmit": true
},
"include": ["src/**/*.ts"]
}Worker 코드 작성
// src/index.ts
export interface Env {
DB: D1Database;
APP_ENV: string;
LOG_LEVEL: string;
API_SECRET: string; // wrangler secret put으로 등록
}
// 간단한 라우터
async function handleRequest(request: Request, env: Env): Promise<Response> {
const url = new URL(request.url);
const path = url.pathname;
// CORS 헤더
const corsHeaders = {
"Access-Control-Allow-Origin": "*",
"Access-Control-Allow-Methods": "GET, POST, PUT, DELETE",
"Access-Control-Allow-Headers": "Content-Type, Authorization",
};
if (request.method === "OPTIONS") {
return new Response(null, { headers: corsHeaders });
}
try {
// GET /api/todos — 전체 목록
if (path === "/api/todos" && request.method === "GET") {
const { results } = await env.DB.prepare(
"SELECT * FROM todos ORDER BY created_at DESC"
).all();
return Response.json(results, { headers: corsHeaders });
}
// POST /api/todos — 새 할 일 추가
if (path === "/api/todos" && request.method === "POST") {
const body = await request.json() as { title: string };
if (!body.title?.trim()) {
return Response.json(
{ error: "title is required" },
{ status: 400, headers: corsHeaders }
);
}
const result = await env.DB.prepare(
"INSERT INTO todos (title) VALUES (?) RETURNING *"
).bind(body.title.trim()).first();
return Response.json(result, { status: 201, headers: corsHeaders });
}
// PUT /api/todos/:id/toggle — 완료 토글
const toggleMatch = path.match(/^\/api\/todos\/(\d+)\/toggle$/);
if (toggleMatch && request.method === "PUT") {
const id = parseInt(toggleMatch[1]);
const result = await env.DB.prepare(
"UPDATE todos SET done = NOT done WHERE id = ? RETURNING *"
).bind(id).first();
if (!result) {
return Response.json(
{ error: "Todo not found" },
{ status: 404, headers: corsHeaders }
);
}
return Response.json(result, { headers: corsHeaders });
}
// DELETE /api/todos/:id — 삭제
const deleteMatch = path.match(/^\/api\/todos\/(\d+)$/);
if (deleteMatch && request.method === "DELETE") {
const id = parseInt(deleteMatch[1]);
await env.DB.prepare("DELETE FROM todos WHERE id = ?").bind(id).run();
return Response.json({ deleted: true }, { headers: corsHeaders });
}
// GET /healthz — 헬스체크
if (path === "/healthz") {
return Response.json({
status: "ok",
env: env.APP_ENV,
timestamp: new Date().toISOString(),
});
}
return Response.json({ error: "Not Found" }, { status: 404, headers: corsHeaders });
} catch (err) {
console.error("Unhandled error:", err);
return Response.json(
{ error: "Internal Server Error" },
{ status: 500, headers: corsHeaders }
);
}
}
export default {
fetch: handleRequest,
};D1 스키마와 로컬 실행
# D1 데이터베이스 생성
npx wrangler d1 create todo-db-staging
# → 출력된 database_id를 wrangler.toml에 기입
npx wrangler d1 create todo-db-production
# → 출력된 database_id를 wrangler.toml에 기입
# 스키마 파일 작성
cat > schema.sql <<'EOF'
CREATE TABLE IF NOT EXISTS todos (
id INTEGER PRIMARY KEY AUTOINCREMENT,
title TEXT NOT NULL,
done INTEGER DEFAULT 0,
created_at DATETIME DEFAULT CURRENT_TIMESTAMP
);
EOF
# 로컬 D1에 스키마 적용
npx wrangler d1 execute todo-db-staging --local --file schema.sql
# 로컬 개발 서버 시작
npx wrangler dev --env staging
# 다른 터미널에서 테스트
curl -X POST http://localhost:8787/api/todos \
-H "Content-Type: application/json" \
-d '{"title": "Wrangler CLI 블로그 글 쓰기"}'
curl http://localhost:8787/api/todos
# [{"id":1,"title":"Wrangler CLI 블로그 글 쓰기","done":0,"created_at":"..."}]
curl -X PUT http://localhost:8787/api/todos/1/toggle
# {"id":1,"title":"Wrangler CLI 블로그 글 쓰기","done":1,"created_at":"..."}배포 자동화 — GitHub Actions CI/CD
Wrangler를 GitHub Actions와 연동하면, 코드를 push할 때마다 자동 배포가 이루어집니다.
GitHub Actions 워크플로
# .github/workflows/deploy.yml
name: Deploy Workers
on:
push:
branches: [main]
pull_request:
branches: [main]
jobs:
deploy:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Setup Node.js
uses: actions/setup-node@v4
with:
node-version: "22"
- name: Install dependencies
run: npm ci
# PR이면 staging에 배포
- name: Deploy to staging
if: github.event_name == 'pull_request'
run: npx wrangler deploy --env staging
env:
CLOUDFLARE_API_TOKEN: ${{ secrets.CF_API_TOKEN }}
CLOUDFLARE_ACCOUNT_ID: ${{ secrets.CF_ACCOUNT_ID }}
# main 머지면 production에 배포
- name: Deploy to production
if: github.ref == 'refs/heads/main' && github.event_name == 'push'
run: npx wrangler deploy --env production
env:
CLOUDFLARE_API_TOKEN: ${{ secrets.CF_API_TOKEN }}
CLOUDFLARE_ACCOUNT_ID: ${{ secrets.CF_ACCOUNT_ID }}GitHub 저장소의 Settings → Secrets and variables → Actions에서 CF_API_TOKEN과 CF_ACCOUNT_ID를 등록합니다. Cloudflare 대시보드에서 “Edit Cloudflare Workers” 권한 템플릿으로 API 토큰을 생성하세요.
Wrangler CLI 필수 명령어 치트시트 — 한눈에 보는 핵심 커맨드
일상적으로 사용하는 Wrangler 명령어를 정리합니다:
프로젝트 관리
# 프로젝트 초기화
npx wrangler init
# 로컬 개발 서버
npx wrangler dev
npx wrangler dev --env staging
npx wrangler dev --port 3000
# 배포
npx wrangler deploy
npx wrangler deploy --env production
# 롤백
npx wrangler rollback --env production
# 배포 이력
npx wrangler deployments list시크릿 관리
# 시크릿 CRUD
npx wrangler secret put SECRET_NAME
npx wrangler secret put SECRET_NAME --env production
npx wrangler secret list
npx wrangler secret list --env production
npx wrangler secret delete SECRET_NAME
npx wrangler secret bulk secrets.jsonKV 관리
# 네임스페이스 관리
npx wrangler kv namespace list
npx wrangler kv namespace create MY_KV
npx wrangler kv namespace delete --namespace-id xxx
# 키-값 조작
npx wrangler kv key put --namespace-id xxx "my-key" "my-value"
npx wrangler kv key get --namespace-id xxx "my-key"
npx wrangler kv key delete --namespace-id xxx "my-key"
npx wrangler kv key list --namespace-id xxx
# 벌크 업로드
npx wrangler kv bulk put --namespace-id xxx data.jsonD1 관리
# 데이터베이스 관리
npx wrangler d1 list
npx wrangler d1 create my-database
npx wrangler d1 delete my-database
npx wrangler d1 info my-database
# 쿼리 실행
npx wrangler d1 execute my-database --command "SELECT * FROM users"
npx wrangler d1 execute my-database --file schema.sql
npx wrangler d1 execute my-database --local --file seed.sql
# 마이그레이션
npx wrangler d1 migrations create my-database add_users_table
npx wrangler d1 migrations apply my-database
npx wrangler d1 migrations apply my-database --localR2 관리
# 버킷 관리
npx wrangler r2 bucket list
npx wrangler r2 bucket create my-bucket
npx wrangler r2 bucket delete my-bucket
# 오브젝트 조작
npx wrangler r2 object put my-bucket/path/file.txt --file ./local-file.txt
npx wrangler r2 object get my-bucket/path/file.txt
npx wrangler r2 object delete my-bucket/path/file.txt로그와 모니터링
# 실시간 로그 테일링 (배포된 Worker)
npx wrangler tail
npx wrangler tail --env production
# 필터링
npx wrangler tail --status error
npx wrangler tail --search "database"
npx wrangler tail --ip 192.168.1.100
# JSON 포맷 (파이프라인 연동)
npx wrangler tail --format jsonWrangler 고급 기능
커스텀 빌드
TypeScript·esbuild·webpack 등 커스텀 빌드 파이프라인이 필요할 때:
# wrangler.toml
[build]
command = "npm run build" # 배포·dev 전에 실행될 빌드 명령
cwd = "." # 빌드 실행 디렉토리
watch_dir = ["src", "lib"] # dev 모드에서 감시할 디렉토리들// package.json
{
"scripts": {
"build": "esbuild src/index.ts --bundle --outfile=dist/index.js --format=esm",
"dev": "wrangler dev",
"deploy:staging": "wrangler deploy --env staging",
"deploy:production": "wrangler deploy --env production"
}
}Workers 간 서비스 바인딩
마이크로서비스 패턴으로 여러 Worker를 연결할 때:
# wrangler.toml — API Gateway Worker
[[services]]
binding = "AUTH_SERVICE"
service = "auth-worker"
environment = "production"
[[services]]
binding = "USER_SERVICE"
service = "user-worker"
environment = "production"// src/index.ts — 서비스 바인딩 사용
export interface Env {
AUTH_SERVICE: Fetcher;
USER_SERVICE: Fetcher;
}
export default {
async fetch(request: Request, env: Env): Promise<Response> {
// 내부 HTTP 호출 없이 직접 Worker 간 통신
// 네트워크를 거치지 않으므로 극히 빠름
const authResult = await env.AUTH_SERVICE.fetch(
new Request("https://auth/verify", {
headers: request.headers,
})
);
if (!authResult.ok) {
return new Response("Unauthorized", { status: 401 });
}
const userData = await env.USER_SERVICE.fetch(
new Request("https://users/me")
);
return userData;
},
};wrangler.toml에서 자주 실수하는 것들
- TOML 배열 문법:
[[kv_namespaces]]에서 대괄호 두 겹([[]])은 TOML의 배열 테이블 문법입니다. 한 겹([])으로 쓰면 파싱 에러가 납니다. - 환경 하위 바인딩:
[[env.staging.kv_namespaces]]처럼 환경 접두어를 빠뜨리지 마세요. - compatibility_date 미래 날짜 금지: 오늘 이후 날짜를 넣으면 에러가 발생합니다.
- name 충돌: 같은 계정 내에서 Worker 이름은 유일해야 합니다. 환경별로
name을 다르게 지정하세요.
홈랩 실전 시나리오 — Mac Studio + Synology NAS
이 시리즈의 단골 홈랩 환경에서 Wrangler를 활용하는 실전 시나리오입니다.
시나리오: NAS 백업 상태를 Workers로 모니터링
5화에서 만든 Cloudflare Tunnel로 NAS에 접근하고, 8화의 R2에 백업 로그를 저장하며, 10화의 D1에 이력을 기록하는 모니터링 Worker를 구축합니다.
# Mac Studio에서 프로젝트 생성
mkdir nas-monitor && cd nas-monitor
npm init -y
npm install --save-dev wrangler typescript @cloudflare/workers-types
# D1 생성
npx wrangler d1 create nas-monitor-db
# 시크릿 등록 — NAS 접근용 API 키
npx wrangler secret put NAS_API_TOKEN
# 🌀 Enter a secret value: [Synology DSM API 토큰 입력]
npx wrangler secret put NOTIFICATION_WEBHOOK
# 🌀 Enter a secret value: [Slack/Discord 웹훅 URL 입력]# wrangler.toml
name = "nas-monitor"
main = "src/index.ts"
compatibility_date = "2026-06-01"
compatibility_flags = ["nodejs_compat_v2"]
# 5분마다 실행되는 Cron Trigger
[triggers]
crons = ["*/5 * * * *"]
[[d1_databases]]
binding = "DB"
database_name = "nas-monitor-db"
database_id = "your-db-id-here"
[[r2_buckets]]
binding = "LOGS"
bucket_name = "nas-backup-logs"
[vars]
NAS_ENDPOINT = "https://nas.example.com" # Tunnel 경유 도메인// src/index.ts — NAS 모니터링 Worker
export interface Env {
DB: D1Database;
LOGS: R2Bucket;
NAS_API_TOKEN: string;
NOTIFICATION_WEBHOOK: string;
NAS_ENDPOINT: string;
}
export default {
// Cron Trigger 핸들러
async scheduled(event: ScheduledEvent, env: Env): Promise<void> {
try {
// NAS 상태 확인 (Tunnel 경유)
const response = await fetch(`${env.NAS_ENDPOINT}/webapi/entry.cgi`, {
method: "POST",
headers: {
"Content-Type": "application/x-www-form-urlencoded",
},
body: new URLSearchParams({
api: "SYNO.Core.System",
version: "1",
method: "info",
_sid: env.NAS_API_TOKEN,
}),
});
const data = await response.json() as { success: boolean; data?: unknown };
const status = data.success ? "healthy" : "unhealthy";
const timestamp = new Date().toISOString();
// D1에 이력 기록
await env.DB.prepare(
"INSERT INTO health_checks (status, timestamp, raw_response) VALUES (?, ?, ?)"
).bind(status, timestamp, JSON.stringify(data)).run();
// R2에 상세 로그 저장
await env.LOGS.put(
`health/${timestamp.slice(0, 10)}/${timestamp}.json`,
JSON.stringify({ status, data, checkedAt: timestamp }),
{ httpMetadata: { contentType: "application/json" } }
);
// 이상 감지 시 알림
if (status === "unhealthy") {
await fetch(env.NOTIFICATION_WEBHOOK, {
method: "POST",
headers: { "Content-Type": "application/json" },
body: JSON.stringify({
text: `⚠️ NAS 상태 이상 감지: ${timestamp}`,
}),
});
}
console.log(`Health check: ${status} at ${timestamp}`);
} catch (err) {
console.error("Health check failed:", err);
// 연결 실패도 기록
await env.DB.prepare(
"INSERT INTO health_checks (status, timestamp, raw_response) VALUES (?, ?, ?)"
).bind("error", new Date().toISOString(), String(err)).run();
}
},
// HTTP 핸들러 — 대시보드용
async fetch(request: Request, env: Env): Promise<Response> {
const url = new URL(request.url);
if (url.pathname === "/api/history") {
const { results } = await env.DB.prepare(
"SELECT * FROM health_checks ORDER BY timestamp DESC LIMIT 100"
).all();
return Response.json(results);
}
return Response.json({ service: "nas-monitor", status: "running" });
},
};# 로컬에서 Cron 핸들러 테스트
npx wrangler dev
# 다른 터미널에서 Cron 수동 트리거
curl "http://localhost:8787/__scheduled?cron=*/5+*+*+*+*"
# 배포
npx wrangler deploy트러블슈팅 — 자주 만나는 문제와 해결
1. “Could not resolve” 인증 에러
# 증상: wrangler deploy 시 인증 실패
# 해결: 토큰 재발급 후 재로그인
wrangler logout
wrangler login2. wrangler dev 포트 충돌
# 증상: Error: listen EADDRINUSE :::8787
# 해결: 다른 포트 사용
npx wrangler dev --port 8788
# 또는 기존 프로세스 종료 (Mac)
lsof -ti:8787 | xargs kill -93. D1 로컬과 리모트 스키마 불일치
# 증상: 로컬에서는 되는데 배포하면 "table not found"
# 원인: 로컬 D1과 리모트 D1은 별개
# 해결: 리모트에도 스키마 적용
npx wrangler d1 execute my-database --remote --file schema.sql4. 환경별 바인딩 누락
# 증상: wrangler deploy --env production 시 "binding not found"
# 원인: [env.production] 블록에 바인딩이 빠졌음
# 해결: 환경 블록에 필요한 바인딩을 모두 선언
# 확인 방법 — 설정 검증
npx wrangler deploy --env production --dry-run5. 대용량 Worker 번들 사이즈 초과
# 증상: "Your Worker exceeded the size limit (10 MiB)"
# Free 플랜: 1 MiB, Paid 플랜: 10 MiB
# 해결 1: 불필요한 의존성 제거
npm ls --all # 의존성 트리 확인
# 해결 2: 외부 모듈은 dynamic import
# 해결 3: 큰 데이터는 KV/R2로 분리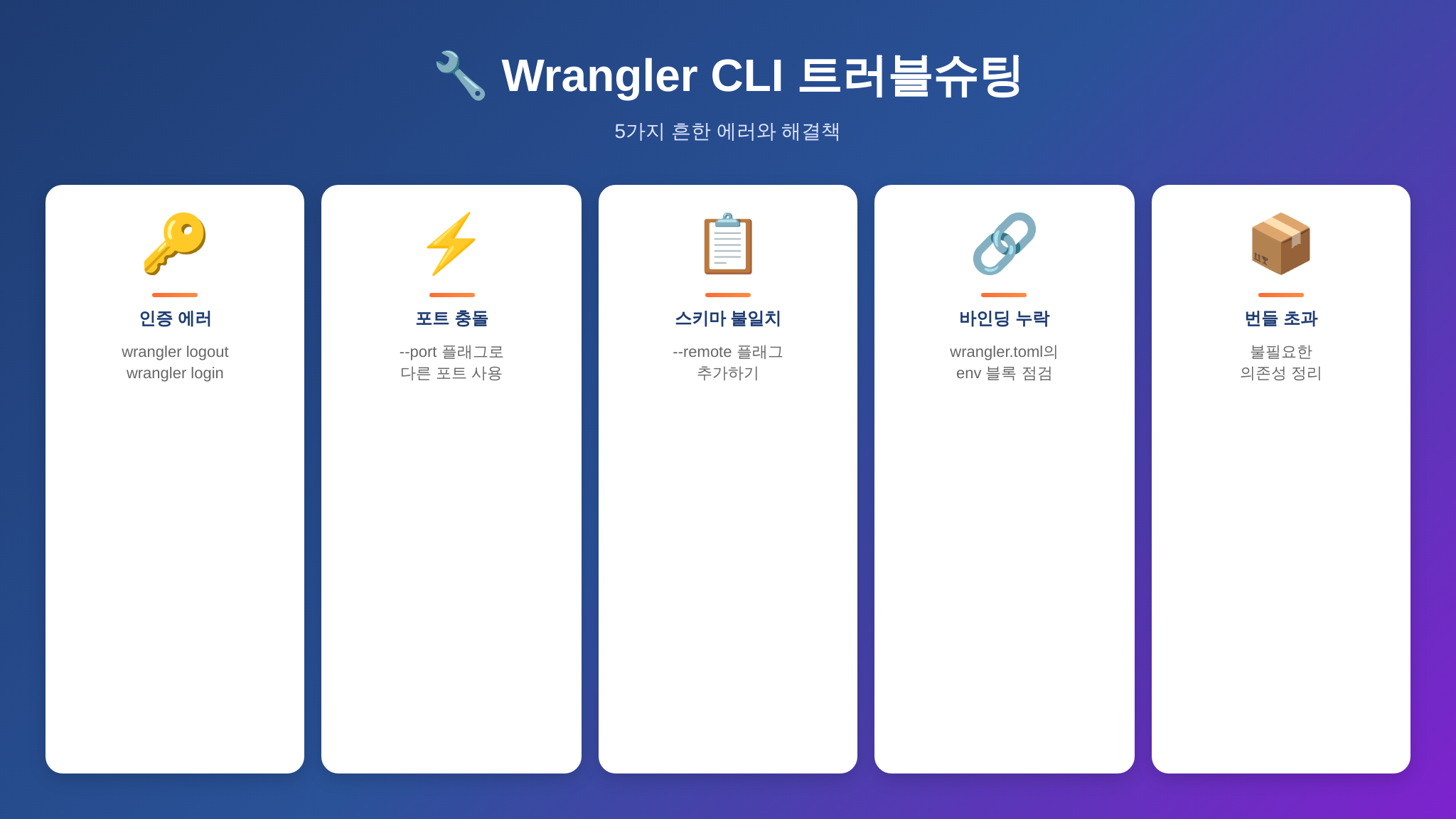
보안 베스트 프랙티스
Wrangler를 사용할 때 꼭 지켜야 할 보안 수칙입니다:
- .gitignore 필수 항목:
# .gitignore — Wrangler 프로젝트 필수
.dev.vars # 로컬 시크릿
.wrangler/ # 로컬 상태 (D1 데이터 등)
node_modules/
dist/- API 토큰 권한 최소화: CI/CD용 토큰은 “Edit Cloudflare Workers” 템플릿만 부여. Account 전체 관리 권한을 주지 마세요.
- 시크릿은 반드시
wrangler secret put으로:[vars]에 API 키를 넣지 마세요. 커밋 히스토리에 영원히 남습니다. - 환경 분리 철저히: staging에서 production DB에 접근하는 구조는 사고의 시작입니다.
wrangler tail로그 점검: 배포 후wrangler tail --status error로 에러를 실시간 모니터링하세요.
월 비용 명세표
| 항목 | Free 플랜 | Workers Paid ($5/월) | 비고 |
|---|---|---|---|
| Wrangler CLI | 무료 | 무료 | 오픈소스, npm 설치 |
| Workers 요청 | 10만 건/일 | 1,000만 건/월 포함 | 초과 시 $0.30/100만 건 |
| Workers CPU 시간 | 10ms/요청 | 30ms/요청 (30초까지 가능) | Unbound 모델 기준 |
| Worker 번들 크기 | 1 MiB | 10 MiB | 압축 후 기준 |
| 환경(Environments) | 제한 없음 | 제한 없음 | 환경별 독립 배포 |
| 시크릿 수 | Worker당 64개 | Worker당 64개 | 환경별 별도 카운트 |
| Cron Triggers | Worker당 3개 | Worker당 3개 | 최소 1분 간격 |
| D1 데이터베이스 | 5M 읽기/일, 100K 쓰기/일 | 25B 읽기/월, 50M 쓰기/월 | 5GB 스토리지 포함 |
| KV 읽기 | 10만 건/일 | 1,000만 건/월 포함 | 초과 시 $0.50/100만 건 |
| KV 쓰기 | 1,000건/일 | 100만 건/월 포함 | 초과 시 $5.00/100만 건 |
| R2 스토리지 | 10GB | 10GB 포함 | 송신료 $0, 초과 $0.015/GB |
| wrangler tail (로그) | 무료 | 무료 | 실시간 로그 스트리밍 |
| Workers Logs (영속) | – | 포함 | Logpush/Tail Workers |
결론: Wrangler CLI 자체는 완전 무료이며, Free 플랜만으로도 소규모 프로젝트의 전체 개발·배포 파이프라인을 구축할 수 있습니다. staging/production 환경 분리에 추가 비용은 없지만, 각 환경의 Workers·KV·D1 사용량은 별도로 합산됩니다. 본격적인 서비스라면 월 $5의 Workers Paid 플랜이 훨씬 넉넉한 한도를 제공합니다.
마무리 — CLI 위에 세우는 개발자 경험
이번 화에서 Wrangler CLI의 핵심 세 축을 다뤘습니다. 시크릿으로 민감 정보를 안전하게, 환경 분리로 staging과 production을 확실하게, 로컬 개발로 배포 없이 빠르게. 이 세 가지가 갖춰지면 대시보드를 열 일이 거의 없어집니다.
9화에서 만든 첫 Worker, 10화에서 선택한 스토리지, 그리고 이번 화의 Wrangler가 합쳐지면 비로소 실전 수준의 Workers 풀스택 개발 환경이 완성됩니다.
다음 12화에서는 Workers AI — 엣지에서 LLM 추론 돌리기를 다룹니다. Cloudflare의 글로벌 엣지에서 AI 모델을 직접 실행하는 방법, 그리고 이번 화에서 배운 Wrangler로 AI Worker를 로컬에서 개발하고 배포하는 전체 워크플로를 살펴봅니다.
◀ 이전 10화 (다음 차수는 아직 게시되지 않았습니다)
참고 자료
- Cloudflare Docs — Wrangler CLI — Wrangler 설치·설정·명령어를 다루는 Cloudflare 공식 문서
- Cloudflare Docs — wrangler.toml Configuration — wrangler.toml 설정 키 전체 레퍼런스

